近似非常不错
一、数据集与任务介绍
MNIST数据集是一个基本的手写字体识别数据集,该数据原本是包含60000个训练图像和10000个测试图像,但这里我们事先对数据进行了划分,从训练样本中抽取10000个数据作为验证集,所以处理后的数据集包含50000个训练样本(training data)、10000个验证样本(validation data)10000个测试样本(test data),都是28乘以28的分辨率。
我们可以先将数据集从GitHub上Clone下来:
|
|
可以从这个链接了解对该数据集的加载和处理。
这里任务就是构建神经网络来实现对于MNIST数据集的手写字体识别分类。从任务和输入就能够得到大概的网络结构: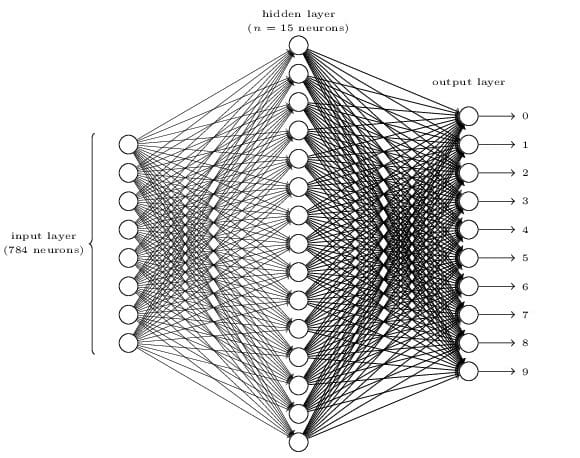
损失函数为平方误差损失函数,激活函数为sigmoid函数。
二、读取数据
读取数据由mnist_loader.py这个文件实现。
代码如下:
|
|
2.1 load_data函数
|
|
load_data()函数的主要作用就是解压数据集,然后从数据集中把数据取出来。取出来之后的几个变量代表的数据的格式分别如下:
training_data:是一个由两个元素构成的元组。其中一个元素是测试图片集合,是一个50000✖️784的numpy ndarray(其中50000行就是样本个数,784列就是一个维度,即一个像素);第二个元素就是一个测试图片的标签集,是一个50000✖️1的Numpy ndarray,其中指明了每一个样本是什么数字,通俗来说就是这个样子:
validation_data 和 test_data 的结构和上面的training_data是一样的,只是数量不一样,这两个是10000行。
2.2 load_data_wrapper()函数
|
|
之前的load_data返回的格式虽然很漂亮,但是并不是非常适合我们这里计划的神经网络的结构,因此我们在load_data的基础上使用load_data_wrapper()函数来进行一点点适当的数据集变换,使得数据集更加适合我们的神经网络训练。
以训练集的变换为例。对于training_inputs来说,就是把之前的返回的training_data[0],即第一个元素的所有样例都放到一个列表中,简单的来说如下所示: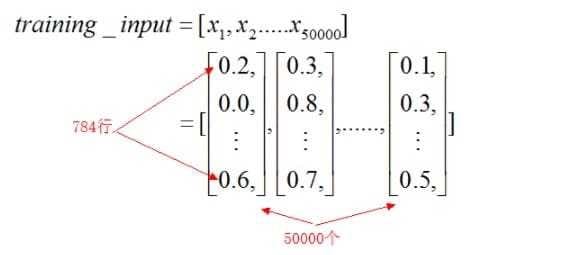
同样可以知道training_labels的样子为: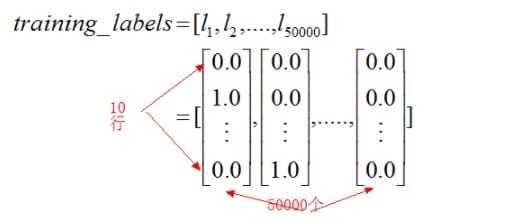
然后training_data为zip函数组合,那么training_data为一个列表,其中每个元素是一个元组,二元组又有一个training_inputs和一个training_labels的元素组合而成,如下图:
同理可以推出其他数据的形状。
三、神经网络
代码如下
|
|
四、结果比较
将隐藏层设为30层,随机梯度下降的迭代次数为30次,小批量数量大小为10,学习速率为3.0
|
|
经过30次迭代之后,神经网络的识别率为95%左右。

