$\chi^2$检验(chi-square test)或称卡方检验,是一种用途较广的假设检验方法,,主要是比较两个及两个以上样本率( 构成比)以及两个分类变量的关联性分析。其根本思想就是在于比较理论频数和实际频数的吻合程度或拟合优度问题。
它的发明者卡尔·皮尔逊是一位历史上罕见的百科全书式的学者,研究领域涵盖了生物、历史、宗教、哲学、法律。在文本分类中可以用卡方值做特征选择(降维),也可以用卡方检验做异常用户的检测。
一、四格表资料的卡方检验
两组大白鼠在不同致癌剂作用下的发癌率如下表,问两组发癌率有无差别?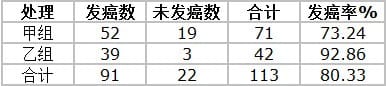
这四格资料表就专称四格表(fourfold table),或称2行2列表(2×2 contingency table)。从该资料算出的两组发癌率分别为73.24%和92.86%,两者的差别可能是抽样误差所致,亦可能是两组发癌率(总体率)确有所不同。这里可通过卡方检验来区别其差异有无统计学意义,检验的基本公式为:
式中A为实际数,以上四格表的四个数据就是实际数。T为理论数,是根据检验假设推断出来的;即假设这两组的发癌率本无不同,差别仅是由抽样误差所致。这里可将两组合计发癌率作为理论上的发癌率,即91/113=80.3%,以此为依据便可推算出四格表中相应的四格的理论数。以表1资料为例检验如下。
检验步骤:
- 1)建立检验假设:$H_0:\ n_1=n_2 \ H_1 : n_1 ≠n_2;$
- 2)计算理论数(TRC),计算公式为:式中$TRC$是表示第R行C列格子的理论数,$n_r$是与理论数同行的合计数,$n_c$是与理论数同列的合计数,$n$为总例数。
第1行1列: 71×91/113=57.18
第1行2列: 71×22/113=13.82
第2行1列: 42×91/113=33.82
第2行2列: 42×22/113=8.18
以推算结果,可与原四项实际数并列成下表: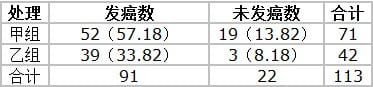
因为上表每行和每列合计数都是固定的,所以只要用TRC式求得其中一项理论数(例如T1.1=57.18),则其余三项理论数都可用同行或同列合计数相减,直接求出。
- 3)计算卡方值按公式代入
- 4)查卡方值表求$P$值
在查表之前应知本题自由度。按卡方检验的自由度v=(行数-1)(列数-1),则该题的自由度v=(2-1)(2-1)=1,查卡方界值表,找到$\chi^2_{0.05}(1)=3.85$,而本题卡方=6.48即卡方>$\chi^2_{0.05}(1)$,P<0.05,差异有显著统计学意义,按α=0.05水准,拒绝H0,可以认为两组发癌率有差别。
通过实例计算,读者对卡方的基本公式有如下理解:若各理论数与相应实际数相差越小,卡方值越小;如两者相同,则卡方值必为零,而卡方永远为正值。又因为每一对理论数和实际数都加入卡方值中,分组越多,即格子数越多,卡方值也会越大,因而每考虑卡方值大小的意义时同时要考虑到格子数。因此自由度大时,卡方的界值也相应增大。
二、四格表卡方值的校正
卡方值表是数理统计根据正态分布中$\chi^2 = \sum (\frac{x_i-\mu }{\sigma})^2$的定义计算出来的。是一种近似。在自由度大于1、理论数皆大于5时,这种近似很好;当自由度为1时,尤其当1<T<5,而n>40时,应用以下校正公式:
例2.某医师用甲、乙两疗法治疗小儿单纯性消化不良,结果小表试比较两种疗法效果有无差异?
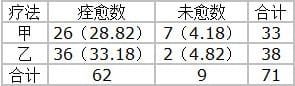
从表可见,T1.2和T2.2数值都<5,且总例数大于40,故宜用校正公式检验。步骤如下:
1)检验假设:$H_0:π1=π2;H_1:π1≠π2;α=0.05$
2)计算理论数:(已完成列入四格表括弧中)
3)计算卡方值:应用校正公式运算如下:
查卡方界值表$\chi^2_{0.05}(1)=3.84$,,故卡方<$\chi^2_{0.05}(1)$,P>0.05。按α=0.05水准,接受H0,两种疗效差异无统计学意义。
如果不采用校正公式,而用原基本公式,算得的结果卡方=4.068,则结论就不同了。
如果观察资料的T<1或n<40时,四格表资料用上述校正法也不行,可参考预防医学专业用的医学统计学教材中的Fisher精确检验法直接计算概率以作判断。
三、行列表的卡方检验
适用于两个组以上的率或百分比差别的显著性检验。其检验步骤与上述相同,简单计算公式如下:
式中n为总例数;A为各观察值;$n_r$和$n_c$为与各A值相应的行和列合计的总数。
例3.北方冬季日照短而南移,居宅设计如何适应以获得最大日照量,增强居民体质,减少小儿佝偻病,实属重要。胡氏等1986年在北京进行住宅建筑日照卫生标准的研究,对214幢楼房居民的婴幼儿712人体检,检出轻度佝偻病333例,比较了居室朝向与患病的关系。现将该资料归纳如表4作行列检验。
该表资料由2行4列组成,称2×4表,可用行×列卡方公式检验。
- 1)检验假设:H0:四类朝向居民婴幼儿佝偻病患病率相同;H1:四类朝向居民婴幼儿佝偻病患率不同;α=0.05
- 2)计算卡方值:
- 3)确定P值和分析:本题v=(2-1)(4-3)=3,据此查卡方界值表:$\chi^2_{0.05}(3)=7.81$,本题卡方=15.08,卡方> $\chi^2_{0.05}(3)$,P<0.05,拒绝$H_0$,可以认为居室朝向不同的居民,婴幼儿佝偻病患病率有差异。
一般认为行列表中不宜有1/5以上格子的理论数小于5,或有小于1的理论数。当理论数太小可采取下列方法处理:①增加样本含量以增大理论数;②删去上述理论数太小的行和列;③将太小理论数所在行或列与性质相近的邻行邻列中的实际数合并,使重新计算的理论数增大。由于后两法可能会损失信息,损害样本的随机性,不同的合并方式有可能影响推断结论,故不宜作常规方法。另外,不能把不同性质的实际数合并,如研究血型时,不能把不同的血型资料合并。
如检验结果拒绝检验假设,只能认为各总体率或总体构成比之间总的来说有差别,但不能说明它们彼此之间都有差别,或某两者间有差别。
四、应用场景
卡方检验的一个典型应用场景是衡量特定条件下的分布是否与理论分布一致,比如:特定用户某项指标的分布与大盘的分布是否差异很大,这时通过临界概率可以合理又科学的筛选异常用户。
另外,x2值描述了自变量与因变量之间的相关程度:x2值越大,相关程度也越大,所以很自然的可以利用x2值来做降维,保留相关程度大的变量。再回到刚才新闻分类的场景,如果我们希望获取和娱乐类别相关性最强的100个词,以后就按照标题是否包含这100个词来确定新闻是否归属于娱乐类,怎么做?很简单,对娱乐类新闻标题所包含的每个词按上述步骤计算x2值,然后按x2值排序,取x2值最大的100个词。

