具体讲解之前,有一点,再次强调下:B-树,即为B树。因为B树的原英文名称为B-tree,而国内很多人喜欢把B-tree译作B-树,其实,这是个非常不好的直译,很容易让人产生误解。如人们可能会以为B-树是一种树,而B树又是一种一种树。而事实上是,B-tree就是指的B树。特此说明。
一、B树
B树(B-tree)是一种树状数据结构,能够用来存储排序后的数据。这种数据结构能够让查找数据、循序存取、插入数据及删除的动作,都在对数时间内完成。B树,概括来说是一个一般化的二叉查找树,可以拥有多于2个子节点。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。这种数据结构常被应用在数据库和文件系统的实作上。
在B树中查找给定关键字的方法是,首先把根结点取来,在根结点所包含的关键字K1,…,Kn查找给定的关键字(可用顺序查找或二分查找法),若找到等于给定值的关键字,则查找成功;否则,一定可以确定要查找的关键字在Ki与Ki+1之间,Pi为指向子树根节点的指针,此时取指针Pi所指的结点继续查找,直至找到,或指针Pi为空时查找失败。
B树作为一种多路搜索树(并不是二叉的):
- 定义任意非叶子结点最多只有M个儿子;且M>2;
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M];
- 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
- 非叶子结点的关键字个数=指向儿子的指针个数-1;
- 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
- 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
- 所有叶子结点位于同一层;
如下图为一个M=3的B树示例: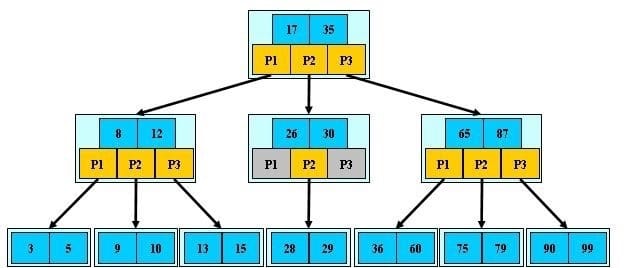
二、B+树
B+树是B树的变体,也是一种多路搜索树,其定义基本与B-树相同,除了:
- 1)非叶子结点的子树指针与关键字个数相同;
- 2)非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
- 3)为所有叶子结点增加一个链指针;
- 4)所有关键字都在叶子结点出现;
B+树的搜索与B树也基本相同,区别是B+树只有达到叶子结点才命中(B树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+树的性质:
- 1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 2.不可能在非叶子结点命中;
- 3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 4.更适合文件索引系统。
三、B*树
$B^*$树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针,将结点的最低利用率从1/2提高到2/3。
$B^*$树定义了非叶子结点关键字个数至少为$\frac{2}{3}M$,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
$B^*$树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,$B^*$树分配新结点的概率比B+树要低,空间使用率更高。

