最短路径问题是图论研究中的一个经典算法问题,旨在寻找图(由结点和路径组成的)中两结点之间的最短路径。算法具体的形式包括:
- 确定起点的最短路径问题 - 即已知起始结点,求最短路径的问题。适合使用Dijkstra算法。
- 确定终点的最短路径问题 - 与确定起点的问题相反,该问题是已知终结结点,求最短路径的问题。在无向图中该问题与确定起点的问题完全等同,在有向图中该问题等同于把所有路径方向反转的确定起点的问题。
- 确定起点终点的最短路径问题 - 即已知起点和终点,求两结点之间的最短路径。
- 全局最短路径问题 - 求图中所有的最短路径。适合使用Floyd-Warshall算法。
一、Dijkstra算法
1.1 算法思想
Dijkstra(迪杰斯特拉)算法是典型的单源最短路径算法,用于计算一个节点到其他所有节点的最短路径。主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。Dijkstra算法是很有代表性的最短路径算法,在很多专业课程中都作为基本内容有详细的介绍,如数据结构,图论,运筹学等等。注意该算法要求图中不存在负权边。
问题描述:
在无向图 G=(V,E) 中,假设每条边 E[i] 的长度为 w[i],找到由顶点 V0 到其余各点的最短路径。(单源最短路径)
算法思想:
设G=(V,E)是一个带权有向图,把图中顶点集合V分成两组,第一组为已求出最短路径的顶点集合(用S表示,初始时S中只有一个源点,以后每求得一条最短路径 , 就将加入到集合S中,直到全部顶点都加入到S中,算法就结束了),第二组为其余未确定最短路径的顶点集合(用U表示),按最短路径长度的递增次序依次把第二组的顶点加入S中。在加入的过程中,总保持从源点v到S中各顶点的最短路径长度不大于从源点v到U中任何顶点的最短路径长度。此外,每个顶点对应一个距离,S中的顶点的距离就是从v到此顶点的最短路径长度,U中的顶点的距离,是从v到此顶点只包括S中的顶点为中间顶点的当前最短路径长度。
适用条件与限制
- 有向图和无向图都可以使用本算法,无向图中的每条边可以看成相反的两条边。
- 用来求最短路的图中不能存在负权边。(可以利用拓扑排序检测)
1.2 算法步骤
- 初始时,S只包含源点,即S={v},v的距离为0。U包含除v外的其他顶点,即:U={其余顶点},若v与U中顶点u有边,则
从U中选取一个距离v最小的顶点k,把k,加入S中(该选定的距离就是v到k的最短路径长度)。
以k为新考虑的中间点,修改U中各顶点的距离;若从源点v到顶点u的距离(经过顶点k)比原来距离(不经过顶点k)短,则修改顶点u的距离值,修改后的距离值的顶点k的距离加上边上的权。
- 重复步骤b和c直到所有顶点都包含在S中。
步骤动画如下:
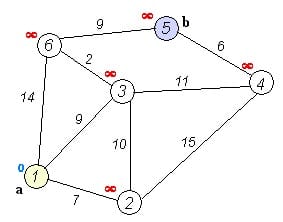
实例如下
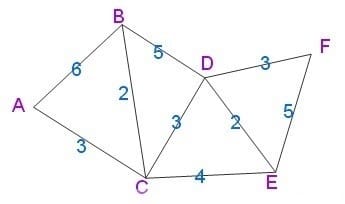
用Dijkstra算法找出以A为起点的单源最短路径步骤如下

1.3 代码实现
以”邻接矩阵”为例对迪杰斯特拉算法进行说明。
|
|
MatrixUDG是邻接矩阵对应的结构体。mVexs用于保存顶点,mEdgNum用于保存边数,mMatrix则是用于保存矩阵信息的二维数组。例如,mMatrix[i][j]=1,则表示”顶点i(即mVexs[i])”和”顶点j(即mVexs[j])”是邻接点;mMatrix[i][j]=0,则表示它们不是邻接点。
|
|
1.4 时间复杂度
我们可以用大O符号将该算法的运行时间表示为边数m和顶点数n的函数。
对于基于顶点集Q的实现,算法的运行时间是$O(|E|\cdot dk_{Q}+|V|\cdot em_{Q})$,其中$dk_{Q}和em_{Q}$分别表示完成键的降序排列时间和从Q中提取最小键值的时间。
Dijkstra算法最简单的实现方法是用一个链表或者数组来存储所有顶点的集合Q,所以搜索Q中最小元素的运算(Extract-Min(Q))只需要线性搜索 Q中的所有元素。这样的话算法的运行时间是$O(n^{2})$。
对于边数少于$n^{2}$的稀疏图来说,我们可以用邻接表来更有效的实现该算法。同时需要将一个二叉堆或者斐波纳契堆用作优先队列来寻找最小的顶点(Extract-Min)。当用到二叉堆的时候,算法所需的时间为${\displaystyle O((m+n)logn)}$,斐波纳契堆能稍微提高一些性能,让算法运行时间达到${\displaystyle O(m+nlogn)}$。然而,使用斐波纳契堆进行编程,常常会由于算法常数过大而导致速度没有显著提高。
二、Floyd算法
Dijkstra很优秀,但是使用Dijkstra有一个最大的限制,就是不能有负权边。而Bellman-Ford适用于权值可以为负、无权值为负的回路的图。这比Dijkstra算法的使用范围要广。
2.1 算法思想
Floyd算法是一个经典的动态规划算法。用通俗的语言来描述的话,首先我们的目标是寻找从点i到点j的最短路径。从动态规划的角度看问题,我们需要为这个目标重新做一个诠释(这个诠释正是动态规划最富创造力的精华所在)
从任意节点i到任意节点j的最短路径不外乎2种可能,1是直接从i到j,2是从i经过若干个节点k到j。所以,我们假设Dis(i,j)为节点u到节点v的最短路径的距离,对于每一个节点k,我们检查Dis(i,k) + Dis(k,j) < Dis(i,j)是否成立,如果成立,证明从i到k再到j的路径比i直接到j的路径短,我们便设置Dis(i,j) = Dis(i,k) + Dis(k,j),这样一来,当我们遍历完所有节点k,Dis(i,j)中记录的便是i到j的最短路径的距离。
2.2 算法步骤
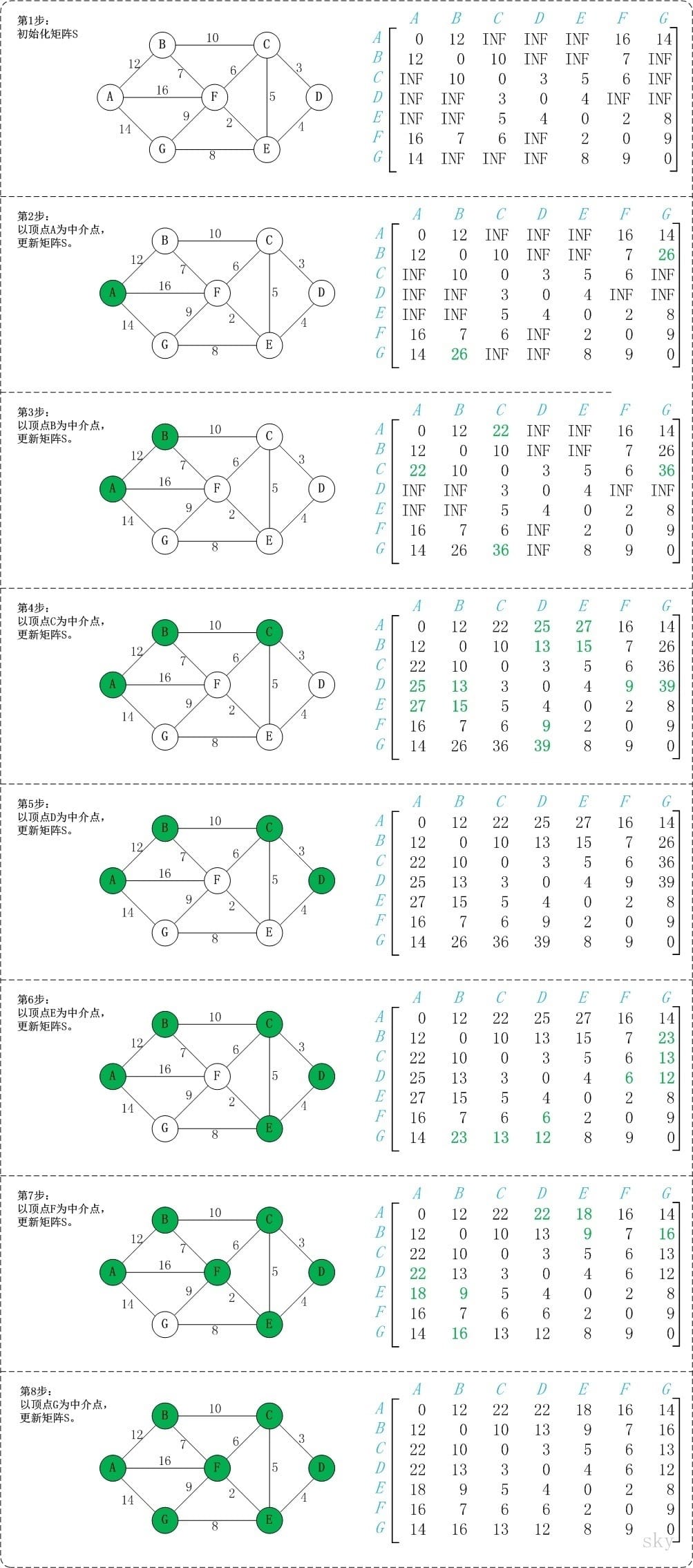
初始状态:S是记录各个顶点间最短路径的矩阵。
初始化S:矩阵S中顶点a[i][j]的距离为顶点i到顶点j的权值;如果i和j不相邻,则a[i][j]=∞。实际上,就是将图的原始矩阵复制到S中。
注:a[i][j]表示矩阵S中顶点i(第i个顶点)到顶点j(第j个顶点)的距离。以顶点A(第1个顶点)为中介点,若$a[i][j] > a[i][0]+a[0][j]$,则设置$a[i][j]=a[i][0]+a[0][j]$。 以顶点$a[1]$,上一步操作之后,$a[1][6]=∞$;而将A作为中介点时,(B,A)=12,(A,G)=14,因此B和G之间的距离可以更新为26。
- 同理,依次将顶点B,C,D,E,F,G作为中介点,并更新a[i][j]的大小。
2.3 代码实现
以”邻接矩阵”为例对弗洛伊德算法进行说明,对于”邻接表”实现的图在后面会给出相应的源码。
|
|
MatrixUDG是邻接矩阵对应的结构体。mVexs用于保存顶点,mEdgNum用于保存边数,mMatrix则是用于保存矩阵信息的二维数组。例如,mMatrix[i][j]=1,则表示”顶点i(即mVexs[i])”和”顶点j(即mVexs[j])”是邻接点;mMatrix[i][j]=0,则表示它们不是邻接点。
|
|
2.4 时间复杂度
Floyd-Warshall算法的时间复杂度为$O(N^{3})$,空间复杂度为$O(N^{2})$。

