对文本进行处理在数据科学实践中必不可少的一环,业界的文本数据往往杂乱无章,而且数量及其庞大,当我们需要对文本进行片段匹配时,就要求我们利用计算机来批量地在文本中检索某种模式。正则表达式(Regular Expression)就是可以进行文本匹配的一种高级模式,它是一些由字符和特殊符号组成的字符串,它可以按照某种模式匹配一系列有相似特征的字符串。
最简单的正则表达式就是普通字符串,它仅仅可以匹配其自身。比如正则表达式“python”只可以匹配字符串“python”。正则表达式的强大之处在于特殊符号的应用,特殊符号定义了字符集合、子组匹配以及模式的重复次数。正是这些特殊符号使得一个正则表达式可以匹配字符串集合而不只是一个字符串。
一、元字符
下图列出了Python支持的正则表达式元字符和语法: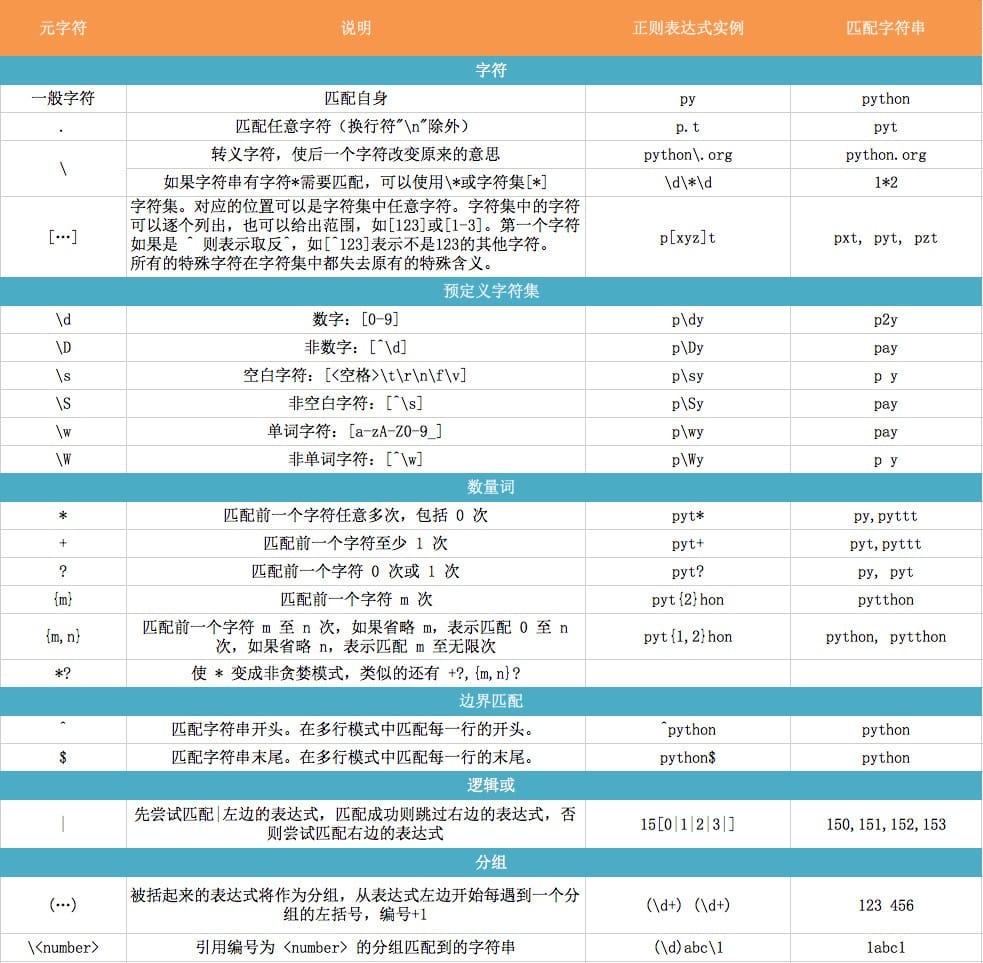
1.1 择一匹配符号“|”
表示从多个模式中选择一个,用于分割不同的正则表达式,可以匹配不止一个字符串,等同于逻辑“或”。例如
|
|
1.2 任意字符匹配符号“.”
“.”号可以匹配除了换行符以为的任何字符(Python正则表达式有一个编译标记[S或DOTALL]能够使“.”匹配换行符),要匹配“.”号自身,必须使用反斜线转译符号“.”。例如:
|
|
1.3 匹配字符串开始“^”或结尾“$”
匹配字符串以什么开始的,可以使用脱字符“^”或\A;
匹配字符串以什么结束的,可以使用美元符“$”或\Z;
例如:
|
|
1.4 匹配单词边界:“\b”、“\B”
\b:匹配单词的边界(单词前或后),而不在乎单词中间的字符
\B:匹配单词中间的字符,而不在乎单词边界的字符
例如:
|
|
1.5 字符集“[ ]”
当想要匹配指定的某些字符的时候,使用字符集是很方便的。
注意:字符集只适用于单字符的情况。也就是说[ab]表示只从ab中选择一个
|
|
1.6 字符集中的范围“-”和否定“”
-:表示一个字符的范围
^:不匹配指定字符集里的任意字符
|
|
1.7 特殊符号(*,+,?,{})
*:匹配其左边的正则表达式出现零次或多次的情况。
+:匹配一次或多次出现的正则表达式。
?:匹配零次或一次出现的正则表达式。
{N}、{M,N}: 匹配前面的正则表达式N次或M~N次
|
|
1.8 特殊字符
\d:十进制数字,相当于[0-9]
\D:非十进制数字的字符,相当于0-9
\w:全部字母数字,相当于[A-Za-z0-9]
\W:非字母数字的字符,相当于A-Za-z0-9
\s: 空格字符
\S: 非空格字符
|
|
1.9 圆括号指定分组
有时候除了进行匹配操作外,我们还想要提取所匹配的子组,例如:\w+-\d+,这个正则表达式想要分别保存第一部分的字母和第二部分的数字,该怎么实现?我们可能这样做的原因是对于任何成功的匹配,我们想要看到匹配的字符串究竟是什么。如果为两个子模块都加上圆括号,例如(\w+)-(\d),然后就能够分别访问每一个匹配的子组。
|
|
1.10 扩展表示法
可以参考上面表格的讲解结合下面的例子就能懂了:
|
|
二、re模块
Python语言中使用re模块的方法支持正则表达式。这里列出re模块常见的函数以方便查询(后面会介绍主要的函数使用方法)

下面将分开解释上面的部分函数:
2.1 使用match()和search()匹配字符串,使用group()查看结果
re.match() :从字符串开始的位置匹配,成功返回匹配的对象,失败返回None
re.search(): 扫描整个字符串来进行匹配,成功返回匹配的对象,失败返回None
例1:比较match() 和 search()的区别
|
|
例2: match()函数从起始位开始匹配
|
|
例3: 匹配多个值(使用择一表达式”|”)
|
|
例4: 匹配任何单个字符。点号”.”除了换行符\n和非字符,都能匹配
|
|
例5: 匹配小数点
|
|
例6: 使用字符集”[ ]”
|
|
例7: 重复、特殊字符
正则表达式: \w+@\w+.com可以匹配类似nobody@xxx.com的邮箱地址,但是类似nobody@xxx.yyy.aaa.com的地址就不能匹配了。这时候我们可以使用 操作符来表示该模式出现零次或者多次:\w+@(\w+.)\w+.com
例8: 分组
group()可以访问每个独立的子组
groups()获取一个包含所有匹配子组的元组
|
|
例9: 匹配字符串起始和结尾
|
|
2.2 使用findall()、finditer()查找每一次出现的位置
final() 以列表的形式返回所有能匹配的结果
|
|
finaliter()返回一个顺序访问每一个匹配结果(Match对象)的迭代器
|
|
2.3 使用sub()和subn()搜索和替换
两个函数都可以实现搜索和替换功能,将某字符串中所有匹配正则表达式的部分进行某种形式的替换。不同点是subn()还返回一个表示替换了多少次的总数,和返回结果一起以元组的形式返回。
|
|
进行替换的时候,还可以指定替换的顺序,原理是使用匹配对象的group()方法除了能够获取匹配分组编号外,还可以使用\N,其中N表示要替换字符串中的分组的编号,通过编号就能指定替换的顺序。
例如:将美式日期MM/DD/YY{,YY}格式转换成DD/MM/YY{,YY}格式
|
|
2.4 在限定模式上使用split()分隔字符串
re模块的split()可以基于正则表达式的模式分隔字符串。但是当处理的不是特殊符号匹配多重模式的正则表达式时,re.split()和str.split()的工作方式相同,如下所示:
|
|
但当处理复杂的分隔时,就需要比普通字符串分隔更强大的处理方式,例如下面匹配复杂情况:
|
|
上述的正则表达式:当一个空格紧跟在5个数字或2个字母后面时就用split语句分隔。当遇到“,”也用split函数分隔。
2.5 扩展符号
通过使用(?iLmsux)系列选项,可以直接在正则表达式里面指定一个活着多个标记。以下是使用re.I/IGNORECASE的示例,第二个是使用re.M/MULTILINE实现多行混合。
|
|
通过使用“多行”,能够在目标字符串中实现跨行搜索,而不必将整个字符串视为单个实体。
下一个例子用来演示re.S/DOTALL,该标记表示点号(.)能够用来表示\n符号。
|
|
re.X/VERBOSE标记允许用户通过抑制在正则表达式中使用空白符来创建更易读的正则表达式。
|
|
(?:…)符号可以对部分正则表达式进行分组,但是不会保存该分组用于后续的检索或应用。
|
|
可以同时使用(?P
|
|
使用后者,可以在同一个正则表达式中重用模式。例如,验证一些电话号码的规范化。
|
|
使用(?x)使代码更易读:
|
|
可以使用(?=…)和(?!…)符号在目标字符串中实现一个前视匹配:
(?=…)字符串后面跟着…才适配
|
|
(?!…)字符串后面不跟着…才适配:
|
|
比较re.findall()和re.finditer()
|
|
条件正则表达式匹配,假定拥有一个特殊字符,它仅仅包含字母x和y,两个字母必须由一个跟着另外一个,不能同时拥有相同的两个字母:
|
|
三、实例
在UNIX系统中,who命令会展示登录的用户信息。例如:
|
|
如果想按照空格(多个,数量不确定)分隔的话,可以使用\s\s+,下面创建一个程序,将保存在文件whodata.txt中的数据读出来:
先将who的数据保存在whodata.txt文件中:
|
|
然后执行下面的程序:
|
|
执行结果:
|
|
优化上面的程序:
上面的程序,who命令是在脚本外部执行的,每次手动重复做这件事让人很厌倦,我们可以通过调用os.popen()命令(现在已经被subprocess模块替代)将这个命令的执行在脚本内部实现。另外我们使用str.rstrip()去除尾部的\n,程序如下:
|
|
还可以使用with语句,可以使上下文管理对象变得更简易:
|
|
如果要适配python2和python3的话,可以避免使用print(),而使用两个版本中都有的函数distutils.log.warn(),并将其转换成printf名来使用。
|
|
生成随机数的例子,用于希望练习从中匹配、搜索正则表达式使用:
|
|

