 扫一扫,关注【应统联盟】公众号,或添加微信 zhanghua63170140
扫一扫,关注【应统联盟】公众号,或添加微信 zhanghua63170140
2018年中国人民大学应用统计初试专业课真题及详细解答,文末附专业课复试笔试真题回忆版。
如有疑问或建议,可添加微信:zhanghua63170140
第一题【10分】
1.1 请说明雷达图和箱线图的基本要点。
1.2 下面的数据集为8个同学的数学、语文和英语的成绩,如何利用雷达图和箱线图来描述这个数据集?
| 姓名 | 数学 | 语文 | 英语 |
|---|---|---|---|
| 甲 | 83 | 86 | 82 |
| 乙 | 93 | 89 | 93 |
| 丙 | 85 | 79 | 90 |
| 丁 | 79 | 81 | 75 |
| 戊 | 79 | 81 | 75 |
| 己 | 75 | 70 | 94 |
| 庚 | 69 | 62 | 94 |
| 辛 | 67 | 62 | 94 |
【解答】
1.1
箱线图由一组数据的最大值、最小值、中位数、上下四分位数这五个特征值绘制而成。不仅反映一组数据分布的特征,如分布是否对称、是否存在离群点等,还可以对多组数据的分布特征进行比较。
雷达图,也称为蜘蛛图,是展示多个变量的常用方法,主要用于比较研究多个样本的相似程度。
1.2
以数学组数据为例绘制箱线图,步骤如下:
画一只箱子,箱子两端分别位于上四分位数和下四分位数。四分位数是指一组数据排序后(67 69 75 79 79 83 85 93)处于$25\%$和$75\%$位置上的值,对于数学组数据来说,下四分位数$Q_1 = 69$以及上四分位数$Q_3 = 83$。这个箱子包括中间$50\%$的数据。
在箱子中位数的位置画一条垂直线,中位数是指一组数据排序后处于中间位置上的变量值。对于数学组数据来说,中位数$M_e=79$。
用四分位数全距$IQR = Q_3 − Q_1$,确定限制线的位置。箱线图的上、下限制线分别在比$Q_1$低$1.5×IQR$和比$Q_3$高$1.5×IQR$的位置上。对于数学组数据来说,$IQR = Q_3 − Q_1 = 83-69 = 14$。因此,限制线的位置在$69− 1.5×14 = 48$和$83 + 1.5×14 =104$处。两条限制线以外的数据可以认为是异常值。但一般限制线不绘制在图上。
绘制触须线。触须线从箱子两端开始绘制,直至最小值和最大值。因此,数学组数据的触须线分别在67和93处结束。
绘制异常值。即处于内限以外位置的点。
以此类推,绘制语文组和英语组的箱线图,得到的箱线图如下: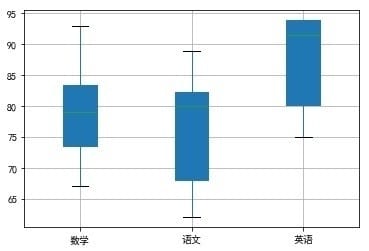
其中中位数位置代表平均水平;箱子长短代表离散程度;分布形状可以看出是否对称。既可以研究单独分析组内数据,也可以对语文、数学、英语三组进行比较研究。我们可以看到,八位同学的英语成绩平均水平最高,数学和语文成绩的离散程度较高,三组成绩都不存在异常值。
雷达图从一个点出发,找到八条射线分别代表八位同学。八个变量的数据点链接起来,围成一个区域,三门课程围成三个区域,研究语文、数学、英语三组成绩的相关比较。从图中可知,多位同学英语成绩的高于其他两门,数学和语文成绩都比较接近。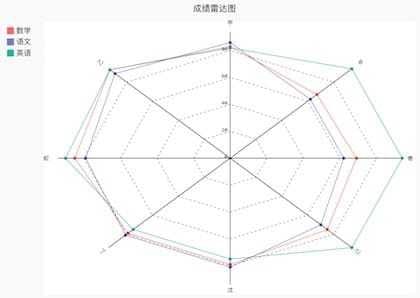
也可以找三条射线,分别代表数学英语和语文三个变量,比较每个学生三门课的成绩。乙同学的三门成绩都比较高,辛同学的三门成绩都较低,需要加倍努力哦。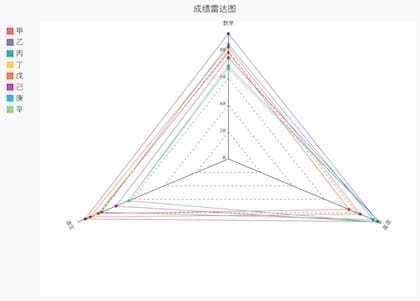
第二题【20分】
2.1 说明在方差已知的条件下,正态总体均值区间估计的宽度与样本量的关系。
2.2 现在有一组来自正态总体的随机样本,可以由此得到在方差已知和方差未知两种条件下的置信区间,请分析这两个置信区间的中点和宽度的异同。
【解答】
2.1
在方差已知的条件下,正态总体均值区间估计的宽度随样本量增大而减小。
在方差已知的条件下,总体分布为正态分布的均值区间估计(无论是大样本还是小样本)为
其中$\bar {x}-z_{\frac{a}{2}}\frac{\sigma}{\sqrt{n}}$称为置信下限,$\bar {x}+z_{\frac{a}{2}}\frac{\sigma}{\sqrt{n}} $称为置信上限;$a$是事先所确定的一个概率值,也被称为风险值,是总体均值不包括在置信区间的概率;$1-a$称为置信水平; 是标准正态分布右侧面积为$\frac{a}{2}$的 Z 值;$z_{\frac{a}{2}}\frac{\sigma}{\sqrt{n}}$是估计总体均值的估计误差。 总体均值的置信区间由两部分组成:点估计值和描述估计量精度的±值,这个±值称为估计误差。
由估计的区间可知,当样本量$n$增大时,区间估计的宽度减小。
2.2
如果是大样本的情况下,方差已知的公式为$\bar {x}±z_{\frac{a}{2}}\frac{\sigma}{\sqrt{n}}$ ,方差未知的公式为$\bar {x}±z_{\frac{a}{2}}\frac{s}{\sqrt{n}}$ 。两个置信区间的中点相同,但是方差未知的情况下是用样本方差替代总体方差,宽度存在差异。
如果在小样本的情况下,方差已知的公式为$\bar {x}±z_{\frac{a}{2}}\frac{\sigma}{\sqrt{n}}$,方差未知的公式为$\bar {x}±t_{\frac{a}{2}}\frac{\sigma}{\sqrt{n}}$ 。两个置信区间的中点相同,但是方差未知的置信区间的宽度会更宽一些。因为选择的t分布与正态分布形状接近,但是两侧的尾端会更宽一些,所构造的置信区间宽度也会更宽。随样本量增大,宽度差异会缩小。
第三题【20分】
3.1 给出一个列联表,写出可以描述上述数据的所有的图形,并说明这些图形的用途,
3.2 写出可以分析上述数据所有可能的方法,并说明用途。
3.1
对于分类型数据可以选择以下图形进行描述性统计分析
- 复式条形图:用宽度相同的条形来表述数据的多少,观察不同类型数据的分布状况。比条形图更便于比较分析
- 帕累托图:按各类别出现的频数多少排序后绘制的条形图,通过排序后,容易看出哪类数据出现的多,哪类出现的少
- 复式饼图:用圆形及圆内扇形的角度来表示数值大小的图形,用于表示各类别的频数占全部频数的比例,适用于研究结构性问题。比之饼图更适用于展示两个或者多个类别变量的构成比较。
- 环形图:显示多个样本各类别频数所占的相应比例,有利于构成的比较研究
3.2
因为以上列联表中有两个分类变量,我们关心这两者是否有关联,可以进行独立性检验,也即进行列联分析。独立性检验就是分析列联表中行变量与列变量是否相互独立,也就是检验性别分布与满意度之间是否存在依赖关系。具体分析步骤如下:
- 提出原假设和备择假设
H0:性别与满意度之间是独立的
H1:性别与满意度之间不独立 - 计算检验统计量
计算$f_o-f)e$,其中$f_e=\frac{RT}{n}×\frac{CT}{n}×n=\frac{RT×CT}{n}$
计算$(f_o-f_e)^2$
计算$\frac{(f_o-f_e)^2}{f_e}$
计算$\sum\frac{(f_o-f_e)^2}{f_e}$ - 做出决策
若$\chi ^2>\chi_a^2$,则拒绝原假设,认为性别与满意度两者之间存在依赖关系。
如果$\chi ^2<\chi_a^2$,则不拒绝原假设,认为两者之间不存在依赖关系。
若拒绝原假设,可继续使用C相关系数或V相关系数测定两者之间的相关关系到底为多少。 通过上面的方法,可以判断两个分类变量是否独立,而当拒绝原假设后,我们可以接着运用对应分析方法来了解两个分类变量即分类变量各个状态之间的相关关系。对应分析利用降维的思想进行简化数据结构,同时对数据表中的行与列进行处理,可把样本点和变量点同时反映到相同的因子轴上,用低维图形简洁明了地揭示两个分类变量之间及分类变量各状态之间的相关关系。
第四题【20分】
设因变量为$y$ ,自变量为$x_1,x_2,x_3·····x_k$,写出建立多元线性回归建模的基本思路。
【解答】
- 提出因变量和自变量:首先根据具体问题选择合适的因变量,然后选择合理的自变量和结合问题的实际意义和专业理论知识,运用逐步回归法等选择自变量。
- 收集整理数据:这是一个重要环节,他直接影响模型的质量。
- 做相关分析,构造多元线性理论回归模型:用SPSS软件计算增广相关阵。
- 用软件计算,输出计算结果(参数估计有最小二乘法和极大似然法等方法):用SPSS软件对原始数据作回归分析。
- 回归诊断:(1)诊断基本假定是否成立(2)相关分析:由复相关系数或决定系数判断回归方程是否显著(3)方差分析表:判断回归方程是否显著(4)回归方程系数显著性检验是否显著(5)检验异常值:判断是否符合实际意义
- 若未通过回归诊断,返回第一步,否则可进入回归应用,主要应用于结构分析、预测和控制三个方面。
第五题【20分】
5.1 方差分析有哪些基本假定?
5.2 简要说明检验这些假定的方法。
【解答】
5.1
方差分析有三大假定
- 正态性:要求每个处理所对应的总体都应服从正态分布
- 方差齐性:要求各处理的总体方差必须想等
- 独立性:要求每个样本数据是来自不同处理的独立样本
5.2
正态性检验:检验正态性可以选择图示法去绘制因变量的正态概率图。包括PP图、qq图或者绘制箱线图、直方图、茎叶图。
- 其中绘制箱线图、直方图、茎叶图观察与正态曲线是否接近;QQ图是根据观测值的实际分位数与理论的分位数绘制的;PP图是根据观测数据的累积概率与理论分布的累积概率的符合程度绘制的;检验正态性还包括检验法包括Shapiro-Wilk和K-S正态性检验,其中Shapiro-Wilk适用于小样本。K-S既可以用于大样本也可以用于小样本
方差齐性检验检验:方差齐性的图示法包括箱线图和残差图。检验法包括Bartlett检验和Levene检验等
- 独立性检验:独立性可以在实验设计之前予以确定,不需要检验
第六题【20分】
在同一个概率空间中是否存在三个随机事件$A,B,C$使得同时成立下面三个不等式:如果存在,请列举一个例子;若不存在,证明你的结论。
【解答】
存在。该题实际是考察辛普森悖论,大家可以自行了解一下。作如下假设:
A事件:被录取
B事件:是男生
C事件:左撇子
B事件和C事件同时发生,即是男生,左撇子有1人
B事件发生,C事件不发生,即是男生,右撇子有4人
B事件不发生,C事件发生,即是女生,左撇子的有4人
B事件不发生,C事件不发生,即是女生,右撇子的有1人
| 男生B | 女生$\bar B$ | |
|---|---|---|
| 左撇子C | 1(录取0人) | 4(录取1人) |
| 右撇子$\bar C$ | 4(录取3人) | 1(录取1人) |
那么
所以
第七题【20分】
设$x_1,x_2······,x_n$为一个来自均值为$\mu$,方差为$\sigma^2$的分布的样本,$\mu$和$\sigma ^2$未知,考虑均值为$\mu$的线性无偏估计类
求出$L$中$T(X)$为$\mu$的无偏估计的充要条件,并求出无偏估计类中方差一致最小的估计。
【解答】
所以$\sum_{i=1}^nc_i=1$
当且仅当$c_i=\frac{1}{n}, \qquad i=1,2,····,n$时,等号成立,即$var[T(X)]=\frac{1}{n}\sigma^2$
所以无偏估计类方差一致最小的估计为$T(X)=\frac{1}{n}\sum_{i=1}^n x_i$
第八题【10分】
设$X$是一个正值随机变量,方差有界,证明:对于$\forall 0<\lambda <1$, 有
【解题】
要证明$P(X>\lambda EX)\quad \geqslant\quad { (1-\lambda ) }^{ 2 }\frac { { (EX) }^{ 2 } }{ E{ X }^{ 2 } } $
即证明$P(X>\lambda EX)·{ EX }^{ 2 }≥\quad { (1-\lambda ) }^{ 2 }·{ (EX) }^{ 2 }$
不等式左边,根据示性函数$I(X-Y)=\begin{cases} 1\quad X-Y>0 \\ 0\quad X-Y≤0 \end{cases}$和定义$P(X>Y)=E[I(X>Y)]$可得
根据柯西不等式$(EXY)^2≤EX^2·EY^2$,得
又因为$X·I(X>\lambda EX)=\begin{cases} X·1\quad X>\lambda EX\quad \\ X·0\quad X≤\lambda EX \end{cases}≥X-\lambda EX$
所以
综合①和③,得到
第九题【10分】
设地区生产总之(亿元)为因变量,固定资产投资(亿元)、社会消费品零售总额(亿元)、出口总额(亿美元)、地方财政收入(亿元)、电力消费量(亿千瓦时)、居民消费水平(元)为自变量,根据31个样本数据得到回归结果如下:
Coefficients
| Estimate | Std. Error | t value | Pr(t) | ||
|---|---|---|---|---|---|
| -2.377 e+03 | 1.166 e+03 | -2.038 | 0.05270 | ||
| 固定资产投资 | 4.504 e-01 | 8.166 e-02 | 5.515 | 1.14 e-05 | * |
| 社会消费品零售总额 | 1.110 e+00 | 1.572 e-01 | 7.060 | 2.68 e-0.7 | * |
| 出口总额 | 1.887 e+01 | 6.379 e+00 | 2.958 | 0.00686 | ** |
| 地方财政收入 | 9.596 e-01 | 6.959 e-01 | 1.379 | 0.18061 | |
| 电力消费量 | 6.683 e-01 | 5.671 e-01 | 1.178 | 0.25016 | |
| 居民消费水平 | 1.194 e-01 | 6.949 e-02 | 1.718 | 0.09868 |
| Residual standard error: | 1526 | 自由度 | 24 |
|---|---|---|---|
| Multiple R-Squared: | 0.9944 | Adjusted R-squared | 0.993 |
| F -statistic: | 708.8 | P-Value | < 2.2 e-16 |
对该回归模型进行综合分析,评价是否需要改进,并给出思路。【10分】
【解答】
- 写出模型,并对每个回归系数进行解释
- 通过了f检验认为因变量与自变量之间线性关系显著
- t检验回归系数是否显著,拒绝原假设时,表明回归系数显著
- 调整的多重判定系数R2=0.993,表示在用样本量和模型中自变量的个数调整后,因变量y的总变差中被多个自变量多共同解释的比例为99.3%
- 通过回归系数的显著性检验和回归系数的正负号判定可能存在多重共线性。还可以计算容忍度$1-R^2$、方差扩大因子$VIF=\frac{1}{1-R^2}$和特征根进一步判断,容忍度越小,多重共线性越严重,容忍度小于1时,存在严重多重共线性,VIF越大,多重共线性越严重,VIF大于10时,存在严重多重共线性;或者对模型中各对自变量之间的相关系数进行显著性检验,通常认为大于0.8高度相关,0.5-0.8是较强的相关关系
- 处理多重共线性可以选择以下方法
a)增加样本容量
b)自变量筛选:根据容忍度和方差因子进行筛选;向前选择;向后剔除;逐步回归
- 前进法: 思想是变量由少到多,每次增加一个,直到没有可以引入的变量为止
- 后退法:首先用全部m个变量建立一个回归方程,然后在这m个变量中选择一个最不重要的变量,将它从方程中剔除
- 逐步回归:思想是有进有出。做法是将变量一个一个引入,每引入一个自变量后,对已选入的变量要进行逐个检验,当原引入的变量优于后面变量的引入而变得不在显著时,要将其剔除
c)放弃无偏估计选择有偏回归(岭回归;主成分回归;偏最小二乘回归)
- 岭回归
- 主成分回归: 构造前M个主成分Z1,…,Zm,然后以这些主成分作为预测变量,用最小二乘拟合线性回归模型
- 偏最小二乘:将原始变量的线性组合Z1,…,Zm作为新的变量集,然后用这M个新变量拟合最小二乘模型
专业课复试笔试真题回忆版
- 给定30个数值型数据,请问如何检验其正态性?
- 给出40个男女生考试分数,其中男生25人,女生15人,问男女生考试分数是否有显著差异,说出检验思路以及该方法的假设条件。
- 多元线性回归模型的基本假定。
- 从获取数据到得出分析结果的过程中会出现误差和干扰,举例说出几种误差以及解决办法。
- 有些统计量中分母会出现总体或样本的方差或标准差,从z检验、t检验和方差分析的角度思考,尽量用文字表述你对这种情况的理解

