参加了历时三天的QCon北京的技术分享大会,一个码农云集的盛会,各大厂拿出自己的看家技术,真的是干货满满。特别感谢金主爸爸给的免费通票和树苗苗姐姐的联络,让我这样的小白加穷学生可以有机会参加这样规模的大会,还加了很多业界大佬的微信,见到了之前膜拜已久的洪强宁老师和张俊林老师,技术交流真的获益匪浅,扩宽了眼界,看到了自己的不足,有很多不懂的地方需要自己慢慢去补课。
下面是一些个人收获比较大的分享内容记录和整理,之后还会慢慢更新。
一、达观数据 陈运文 《文本智能处理的深度学习技术》
人工智能目前的三个主要细分领域为图像、语音和文本,老师分享的是达观数据所专注的文本智能处理领域。文本智能处理,亦即自然语言处理,试图让机器来理解人类的语言,而语言是人类认知发展过程中产生的高层次抽象实体,不像图像、语音可以直接转化为计算机可理解的对象,它的主要应用主要是在智能问答,机器翻译,文本分类,文本摘要,标签提取,情感分析,主题模型等等方面。
自然语言的发展历程经历了以下几个阶段。这里值得一提的是,关于语言模型,早在2000年,百度IDL的徐伟博士提出了使用神经网络来训练二元语言模型,随后Bengio等人在2001年发表在NIPS上的文章《A Neural Probabilistic Language Model》,正式提出神经网络语言模型(NNLM),在训练模型的过程中也能得到词向量。2007年,Mnih和Hinton在神经网络语言模型(NNLM)的基础上提出了log双线性语言模型(Log-Bilinear Language Model,LBL),同时,Hinton在2007年发表在 ICML 上的《Three new graphical models for statistical language modelling》初见其将深度学习搬入NLP的决心。2008年,Ronan Collobert等人 在ICML 上发表了《A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning》,其中的模型名字叫C&W模型,这是第一个直接以生成词向量为目标的模型。LBL与NNLM的区别正如它们的名字所示,LBL的模型结构是一个log双线性结构;而NNLM的模型结构为神经网络结构。这些积淀也成就了Mikolov创造了实用高效的Word2Vec工具,起初,他用循环神经网络RNNLM来做语言模型,发表paper《Recurrent neural network based language model》,之后就是各种改进,博士论文研究的也是用循环神经网络来做语言模型,《Statistical Language Models based on Neural Networks》。2013年,Mikolov等人同时提出了CBOW和Skip-gram模型。使用了Hierarchial Softmax和Negative Sampling两种trick来高效获取词向量。当然这个模型不是一蹴而就的,而是对于前人在NNLM、RNNLM和C&W模型上的经验,简化现有模型,保留核心部分而得到的。同时开源了Word2Vec词向量生成工具,深度学习才在NLP领域遍地开花结果。
一般地,文本挖掘各种类型应用的处理框架如下所示:
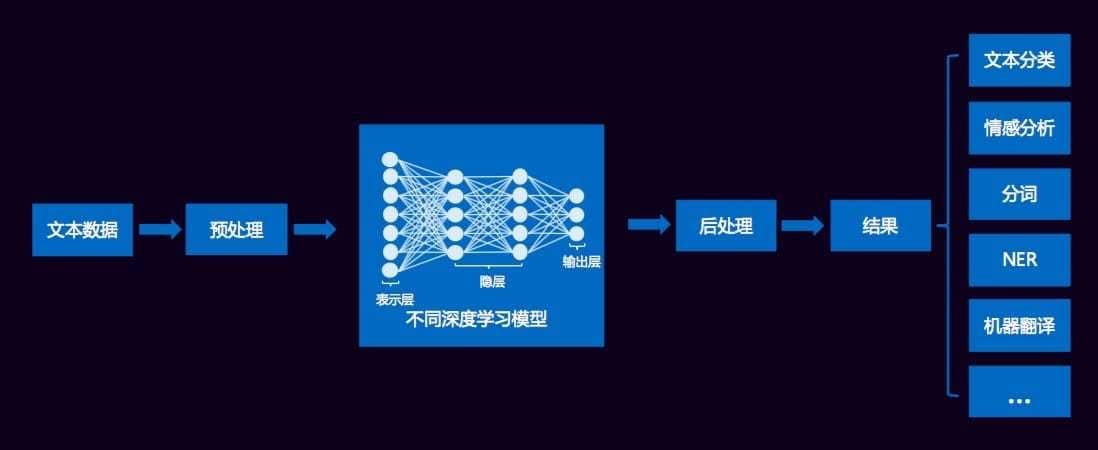
文本数据经过清洗、分词等预处理之后,传统方法通过提取诸如词频、TF-IDF、互信息、信息增益等特征形成高维稀疏的特征集合,而现在则基本对词进行embedding形成低维稠密的词向量,作为深度学习模型的输入,这样的框架可用于文本分类、情感分析、机器翻译等等应用场景,直接端到端的解决问题,也无需大量的特征工程,无监督训练词向量作为输入可带来效果的极大提升。
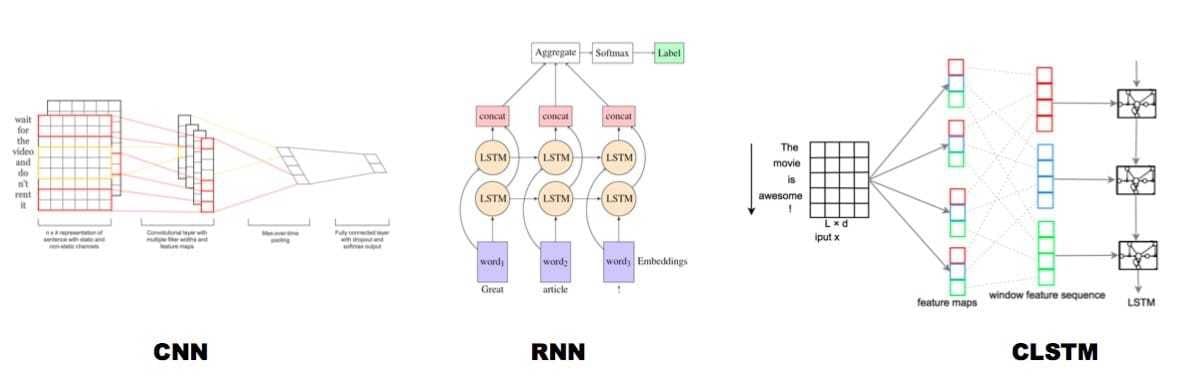
文本分类
对于文本分类,以下列出了几种典型的深度学习模型:
序列标注
序列标注的任务就是给每个汉字打上一个标签,对于分词任务来说,我们可以定义标签集合为:$LabelSet=\{ B,M,E,S\}$。B代表这个汉字是词汇的开始字符,M代表这个汉字是词汇的中间字符,E代表这个汉字是词汇的结束字符,而S代表单字词。下图为中文分词序列标注过程:
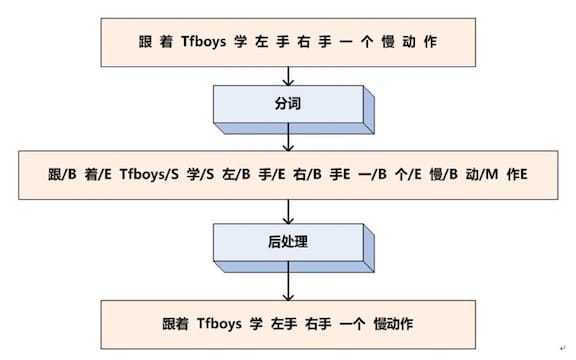
中文分词转换为对汉字的序列标注问题,假设我们已经训练好了序列标注模型,那么分别给每个汉字打上标签集合中的某个标签,这就算是分词结束了,因为这种形式不方便人来查看,所以可以增加一个后处理步骤,把B开头,后面跟着M的汉字拼接在一起,直到碰见E标签为止,这样就等于分出了一个单词,而打上S标签的汉字就可以看做是一个单字词。于是我们的例子就通过序列标注,被分词成如下形式:{跟着 Tfboys 学 左手 右手 一个 慢动作}
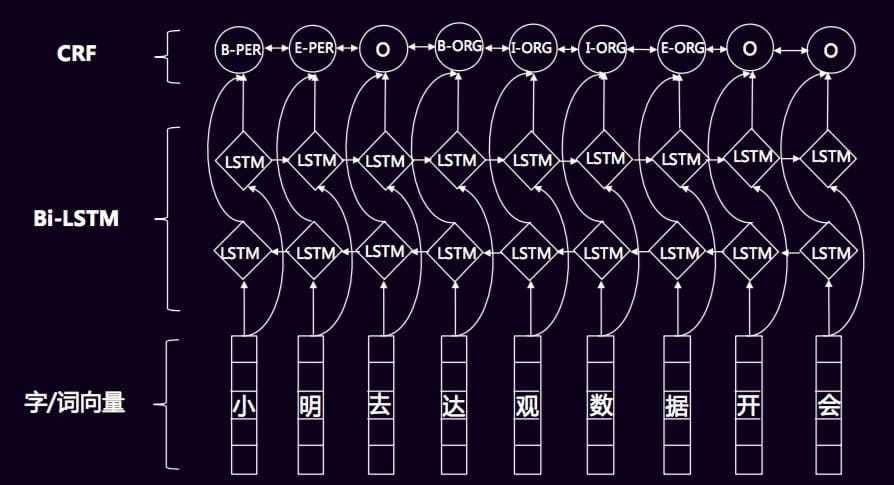
对于序列标注,传统的方法基本是使用大量的特征工程,进入CRF模型,但不同的领域需要进行相应的调整,无法做到通用。而深度学习模型,例如Bi-LSTM+CRF则避免了这样的情况,可以通用于不同的领域,且直接采用词向量作为输入,提高了泛化能力,使用LSTM和GRU等循环神经网络还可以学习到一些较远的上下文特征和一些非线性特征。
经典的Bi-LSTM+CRF模型如下所示:
生成式摘要
对于生成式摘要,采用Encode-Decoder模型结构,两者都为神经网络结构,输入原文经过编码器编码为向量,解码器从向量中提取关键信息,组合成生成式摘要。当然,还会在解码器中引入注意力机制,以解决在长序列摘要的生成时,个别字词重复出现的问题。
此外,在生成式摘要中,采用强化学习与深度学习相结合的学习方式,通过最优化词的联合概率分布,即MLE(最大似然),有监督进行学习,在这里生成候选的摘要集。模型图如下:
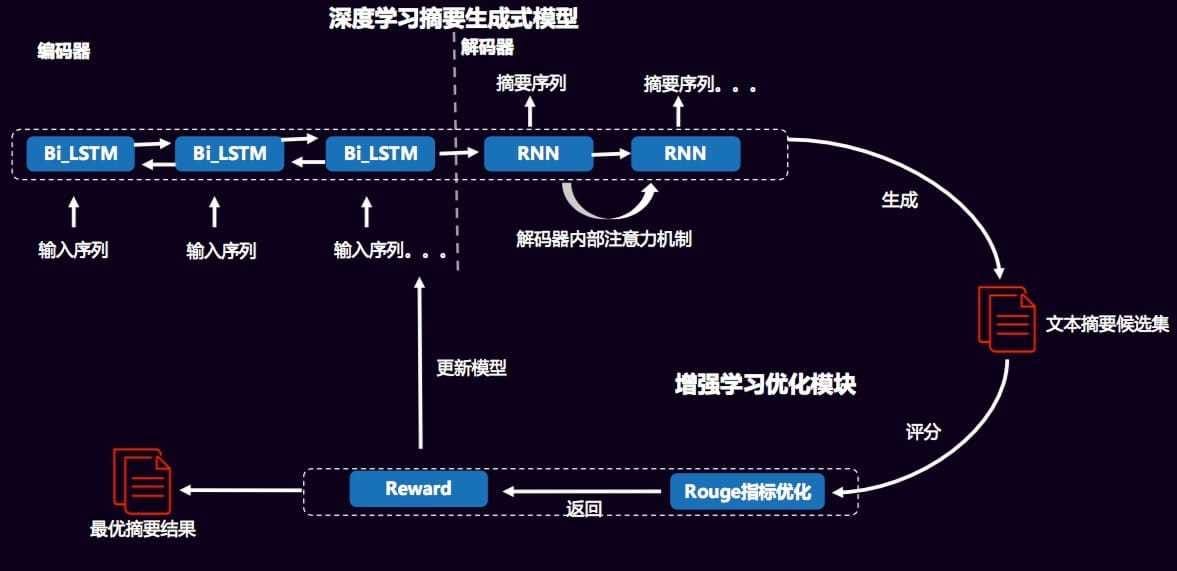
模型图中的ROUGE指标评价是不可导的,所以无法采用梯度下降的方式训练,这样我们就考虑强化学习,鼓励reward高的模型,通过给予反馈来更新模型。最终训练得到表现最好的模型。
知识图谱关系抽取
对于知识图谱的关系抽取,主要有两种方法,一个是基于参数共享的方法,对于输入句子通过共用的 word embedding 层,然后接双向的 LSTM 层来对输入进行编码。然后分别使用一个 LSTM 来进行命名实体识别 (NER)和一个 CNN 来进行关系分类(RC);另一个是基于联合标注的方法,把原来涉及到序列标注任务和分类任务的关系抽取完全变成了一个序列标注问题。然后通过一个端对端的神经网络模型直接得到关系实体三元组。
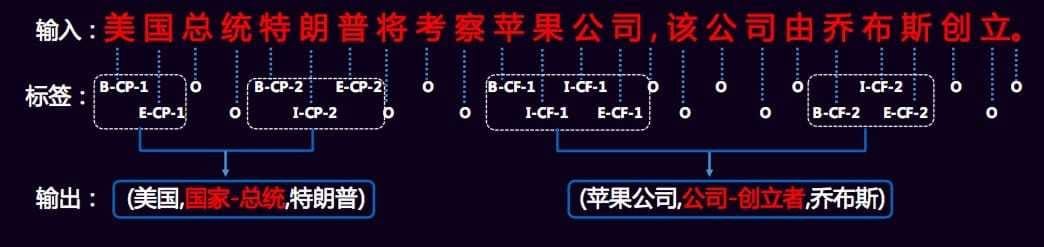
如下图所示,我们有三类标签,分别是 ①单词在实体中的位置{B(begin),I(inside),E(end),S(single)}、②关系类型{CF,CP,…}和③关系角色{1(entity1),2(entity2)},根据标签序列,将同样关系类型的实体合并成一个三元组作为最后的结果,如果一个句子包含一个以上同一类型的关系,那么就采用就近原则来进行配对。
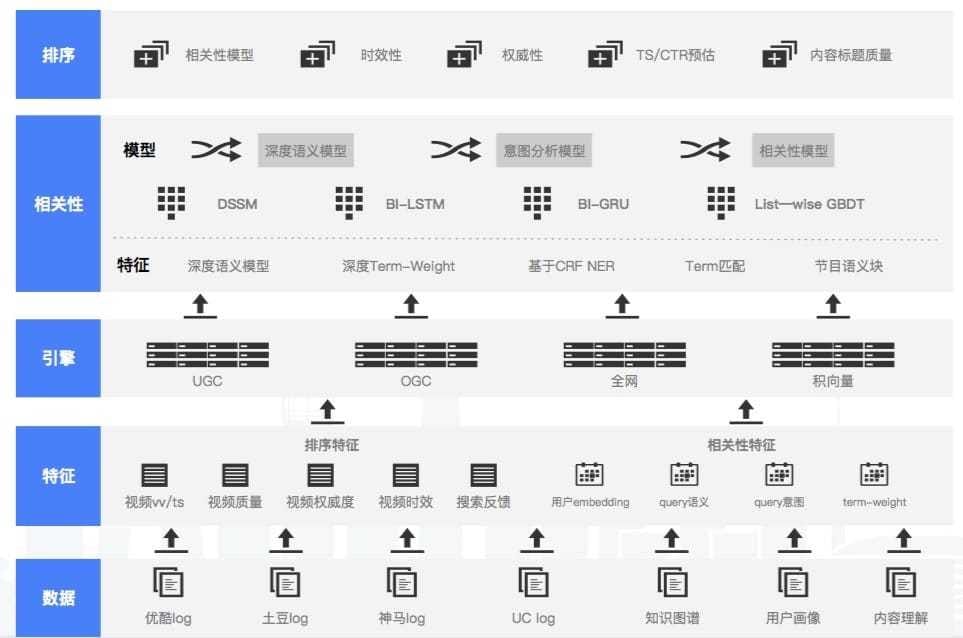
二、爱奇艺 方非 《爱奇艺视频信息流推荐的深度学习之路》
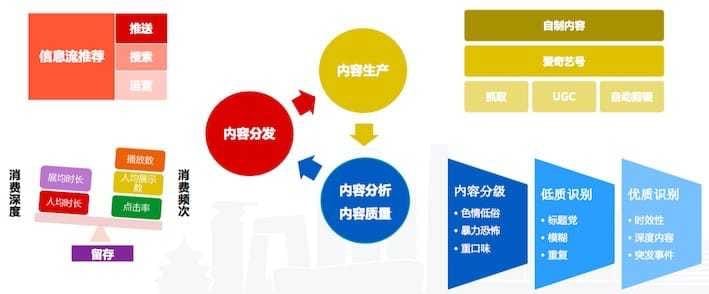
爱奇艺的短视频内容生态主要由OGC(Occupationally-generated Content,职业生产内容)、PGC(Professionally-generated Content,专业生产内容)、UGC(User-generated Content,用户生产内容),布局到PC端、移动端、TV端和VR,通过个性化推荐并使用feed流或者多列瀑布流进行高效内容分发,它的整个内容平台如下所示:
爱奇艺的深度学习架构设计主要分为深度召回模型和深度排序模型,
深度召回模型
召回,即给定上下文{ User, Context },从所有推荐集合中过滤出具备推荐价值的内容{ Item List },推荐价值使用兴趣相关性、热门、好友都在看、关注、LBS等等来定义。
协同过滤方法是基于用户行为来 预测/推荐 的一类算法,它基于这样一种假设:相似的视频更大概率会被同一个用户(相似的用户)看过;相似兴趣的用户会更大概率看同一个视频(相似的视频);历史会重复发生。
基于近邻的协同过滤方法有Item-based CF和User-based CF,虽然实现简单,不依赖内容本身,能得到基本稳定可靠的结果,可解释性强;但是对稀疏性非常敏感,没有考虑行为顺序和上下文变化,难以加入其它特征,高维空间建模,难以和其他模型结合。
基于协同过滤思想的还有其他很多模型,分别如下
- Matrix Factorization :SVD & ALS
- Bayesian Model
- Classification & Clustering
- Embedding:Item2Vec、Neural CF
- Deep Learning:RBM、MLP、LSTM、Attention
概括一下基于Embedding和基于Deep Learning的协同过滤模型
Item2Vec
由Barkan O和Koenigstein N于2016年在论文《Item2Vec: Neural Item Embedding for Collaborative Filtering》中提出, 作者受nlp中运用embedding算法学习word的latent representation的启发,特别是参考了google发布的的word2vec(Skip-gram with Negative Sampling,SGNS),利用item-based CF 学习item在低维 latent space的 embedding representation,优化 item2item的计算。其模型结构如下:
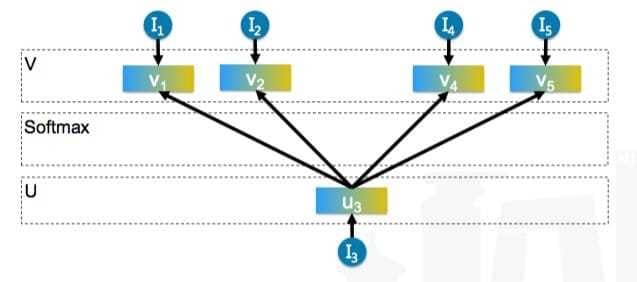
Item2vec中把用户浏览的商品集合等价于word2vec中的word的序列,即句子(忽略了商品序列空间信息spatial information) ,出现在同一个集合的商品对视为 positive。对于集合$w_{1}, w_{2}, …,w_{K}$,模型的目标函数是最大化平均的log概率:
同word2vec,利用负采样,将$p(w_{j}|w_{j})$定义为:
subsample的方式也类似于word2vec,丢弃某一个集合$w_i$的概率为:
最终,利用SGD方法学习参数最大化目标函数,任意Item都能 得到U和V两个一定维度的向量,这样我们得到每个商品的embedding representation,商品之间可以两两计算cosine相似度,即为商品的相似度。这个模型的缺点是相似度的计算只利用到了item的共现信息,忽略了user行为序列信息,且没有建模用户对不同item的喜欢程度高低。
Neural CF
Xiangnan He , Lizi Liao , Hanwang Zhang , Liqiang Nie , Xia Hu , Tat-Seng Chua, Neural Collaborative Filtering, Proceedings of the 26th International Conference on World Wide Web, April 03-07, 2017, Perth, Australia
基于MLP的协同过滤模型
模型结构如下:
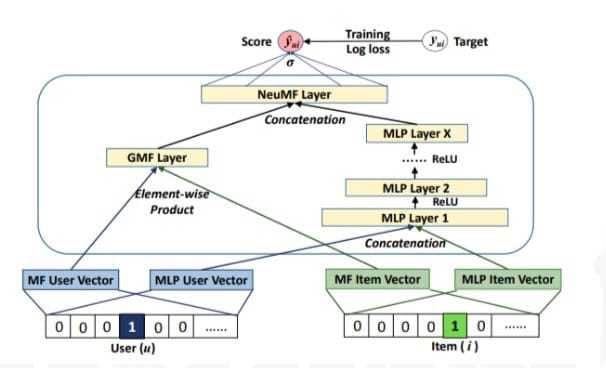
这个模型增加了网络深度,但缺乏时序性考虑,没有其他的特征信息。
LSTM
基于LSTM的协同过滤模型,加入时序性的考虑,但缺乏对历史项重要性的学习,且没有其他的特征信息。模型结构如下:
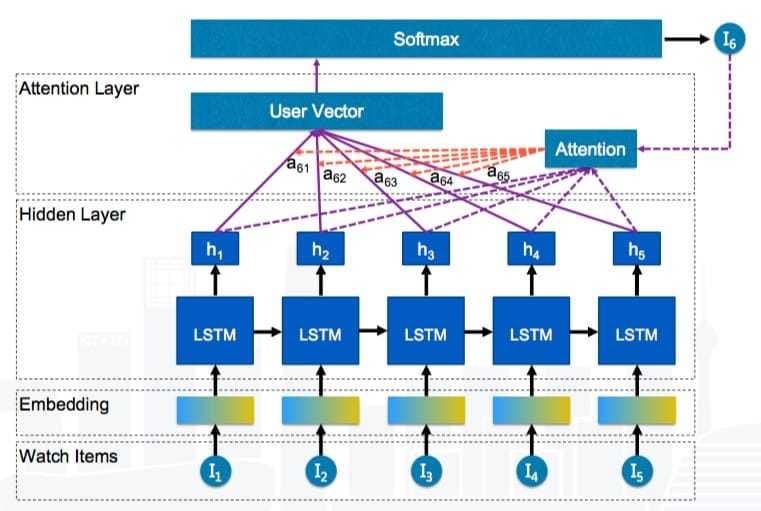
LSTM + Attention
基于LSTM + Attention的协同过滤模型加入时序性考虑,且在LSTM的基础上加入对历史项Attention的学习,但还是存在没有其他的特征信息的问题。模型结构如下:
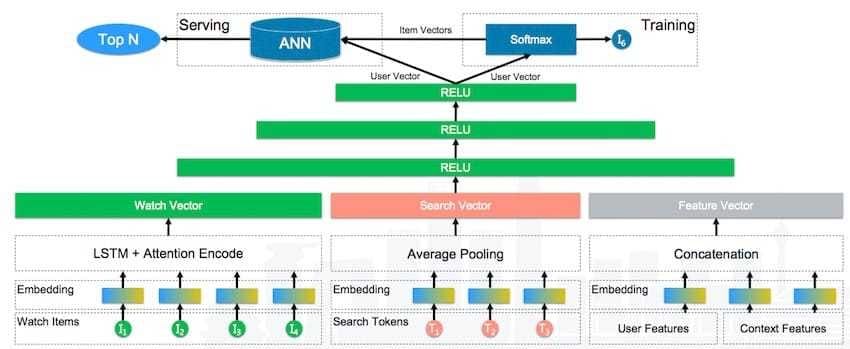
深度召回模型
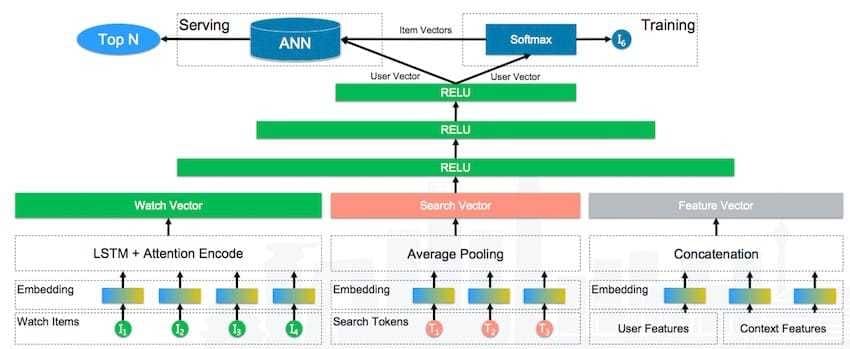
深度排序模型
排序算法,即从召回算法选取的内容集合中,找到最符合推荐预定目标的K个结果。主要有三种,分别是Pointwise、Pairwise、Listwise。
排序模型的四个要素:目标、样本、特征和模型。
- 目标
最终的最大化目标有以下这些,目标有长期与短期之分,也有主次之分,每一个目标都有各自的优化偏重:
| 目标 | 特点 |
|---|---|
| 点击率 | 简单直接,偏短时长 |
| 时长 | 更能反应用户的兴趣,偏长时长 |
| 互动 | 社交属性,稀疏 |
| 关注订阅 | 社交属性,内容生态,稀疏 |
| 留存 | 最接近用户满意度,直接优化难度高 |
当然还会受到许多约束,诸如内容价值观、多样性、时效性、长尾分发、标题党、反作弊等
- 样本
然后根据目标仔细设计样本,将点击、点赞、评论、转发、关注、留存等定义为正样本,把展示不点击、不喜欢、负面评论等定义为负样本,并根据播放时长、反馈类型、样本有效性对样本进行加权。此外,处于样本有效性的考虑,会将无效样本判断过滤掉
- 特征
关于特征,根据特征向量的特点可分为三种:稠密特征、稀疏特征和Embedding特征。
| 稠密特征 | 稀疏特征 | Embedding特征 |
|---|---|---|
| 点击率 | 视频 ID | 标题 Embedding |
| 播放量 | 视频标签 | Item2Vec Embedding |
| 播放时长 | 用户标签 | 图片 Embedding |
| 年龄 | 订阅作者 ID | 社交 Embedding |
| 性别 | LBS | End2End Embedding |
- 模型
关于模型这一块,已经有很成熟的模型可以使用,主要有以下几种:LR、FM、GBDT、GBDT + FM(LR)、DNN+FM
(DeepFM: A Factorization-Machine based Neural Network for CTR Prediction)
这里使用的是基于Wide And Deep思想的多目标分类,模型结构如下: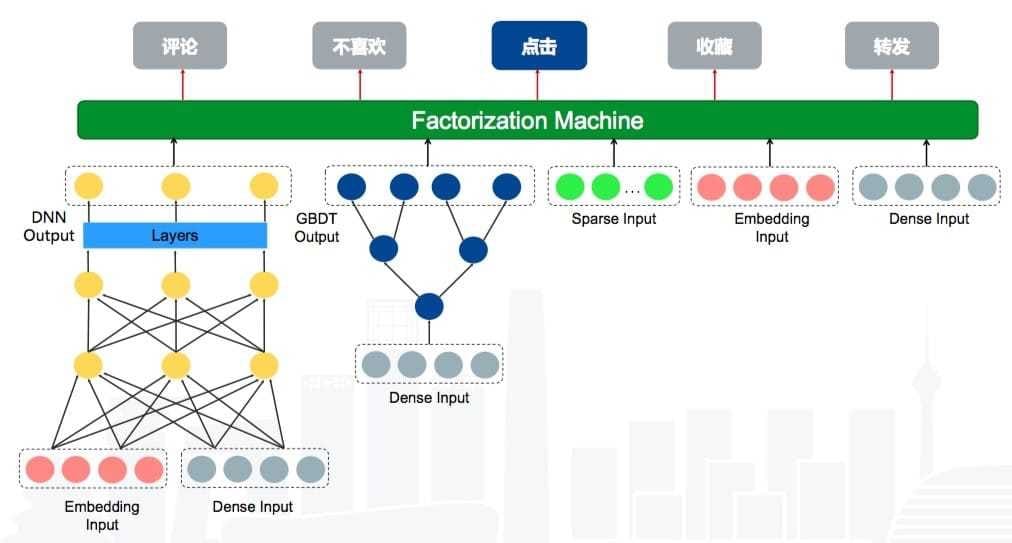
最后是整个排序服务平台的搭建,其组成部分如下所示:

三、优酷 刘尚堃 《深度学习在视频搜索中的应用》
视频搜索的挑战
视频搜索中存在以下这些挑战:
- 非结构化、无组织,这就提升了召回难度
- 短文本、信息不充分,带来语义上的困难
- 海量短视频,给用户选择带来困难
针对这些挑战,提出了一些利用深度学习来解决问题的对策,分别是
- 基于视频内容理解的召回
- 语义模型、语义表征
- 个性化表征
视频内容理解—召回
基于类目标签的召回
输入任意的视频,通过内容理解的方法对视频进行类目和标签的预测。采用的方法是CNN+LSTM的端到端预测方法。
基于事件/场景的召回
给定不定长视频,定位感兴趣行为发生的时间段并给出对应行为类标。采用的方法是Convolution 3D+Gated Recurrent Unit(GRU)算法,结合Single Shot Detector(SSD)框架实现行为检测功能。

基于物体/人物的召回
定位和识别视频中的特定目标,并在目标生命周期内进行跟踪。采用的方法是Region fully convolution network(R-FCN)的深度学习框架,对于小物体在feature map进行了优化;跟踪采用DCF框架,结合颜色模型,并使用BACF进行候选区域扩充。

视频智能封面图
UGC视频智能缩略图,目的是通过对视频进行结构化分析,对关键帧、视频镜头进行筛选和排序,选择最优的关键帧、关键片段来作为视频的展示。采用的方法是用关键帧提取+MMR优化+美学评分等方法,选择视频中最优关键帧作为该视频的首图。
语义搜索—语义表征
人工审核标注ground truth,训练集测试集比例为7:3,加入语义特征后,NDCG提升1%的绝对值。
- 固定数据尝试不同的模型
| 模型 | NDCG |
|---|---|
| 双向LSTM+Attention | 达到0.9以上 |
| BiGRU dropout | 达到0.8以上 |
- 固定模型尝试term embedding初始化方式
| 模型 | 初始化方式 | 长尾query NDCG |
|---|---|---|
| Bi-LSTM+Attention | 随机 | baseline |
| Bi-LSTM+Attention | embedding | 低于baseline 1% |
| Bi-LSTM+Attention | UC/豆瓣的FastText Embedding | 高于baseline 1% |

用户体验优化:
- 在长尾query和语义层面实现了特征增益,在长尾query相关性上有较大改善
- ground truth测试集NDCG提升了1%
技术创新突破
- 基于FastText无监督embedding
- 细粒度+字切分 优酷title语料覆盖度99%
- 训练数据集 billion级别,模型参数量千万级别
- Bi-LSTM+Attention
- 基于pai-tensorflow的分布式训练
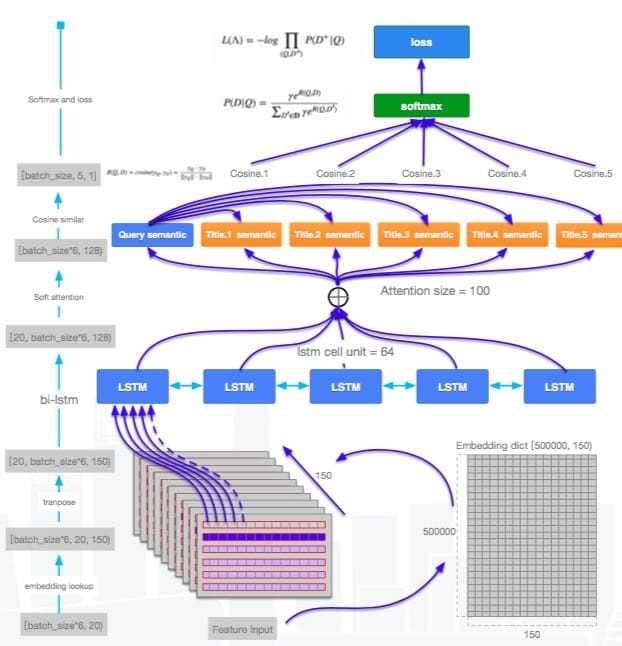
排序—个性化表征
特征按照field进行组织,按照特征重要性和关联性进行分域,分为query field、user field、video field、id field、统计field、用户观看序列、标签兴趣、文本等,形成超高维的稀疏编码来表征独立个体,使得深度特征的组合表达能力达到极致,其模型结构如下:
但这样对在线计算形成了挑战,特征维度高,模型存储空间大,离线训练计算时间成本高,在线实现资源占用高,前向网络计算不能满足RT的要求。就用了一系列的技术,诸如随机编码、挂靠编码、抽样技术等。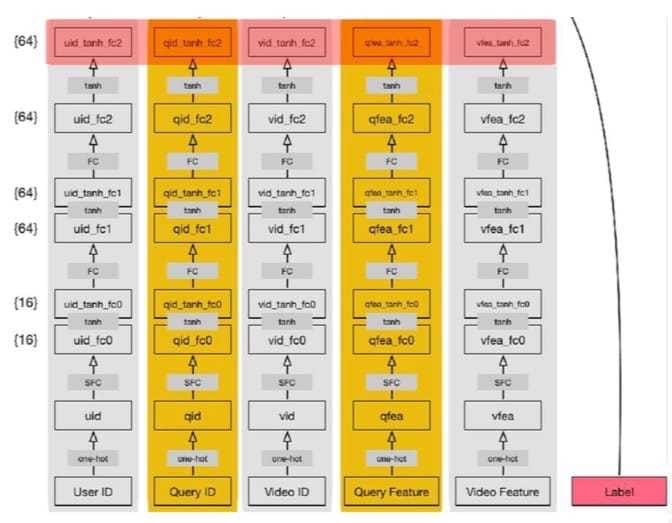
总结