创建
- 从本地文件系统/分布式文件系统HDFS加载:
|
|
- 通过并行集合(数组)创建
|
|
RDD操作
惰性机制:整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”真正的计算。
转换操作
惰性求值,遇到行动操作才会触发“从头到尾”的真正的计算
- filter
- map
- flatmap
- groupByKey
- reduceByKey
行动操作
真正触发计算的地方。
- count():返回元素个数
- collect():以数组形式返回所有元素
- first():返回第一个元素
- take(n):以数组形式返回前n个元素
- reduce(func):通过函数func(输入两个参数并返回一个值)聚合元素
- foreach(func):将每个元素传递到函数func中运行
|
|
- 注意:Local模式单机执行时,rdd.foreach(elem=>println(elem))会打印出一个RDD中的所有元素。但在集群模式下,在Worker节点上执行打印语句是输出到Worker节点的stdout中,而不是输出到任务控制节点Driver中,因此,任务控制节点Driver中的stdout是不会显示打印语句的这些输出内容的。为了能够把所有Worker节点上的打印输出信息也显示到Driver中,就需要使用collect()方法。但collect()方法会把各个Worker节点上的所有RDD元素都抓到Driver中,因此,可能会导致Driver所在节点发生内存溢出。
- 实例
|
|
持久化
为避免重复计算产生的开销,可使用persist()方法对RDD标记为持久化。
- persist(MEMORY_ONLY):将RDD作为反序列化的对象存储于JVM中,若内存不足,按照LRU原则(least recently used最近最少使用原则)替换缓存中的内容。
persist(MEMORY_AND_DISK):将RDD作为反序列化的对象存储于JVM中,若内存不足,超出的分区将会被存放在磁盘上。
cache()方法,会调用persist(MEMORY_ONLY)
|
|
分区
分区的作用:
- 增加并行度:分区可以在不同的工作节点上启动不同的线程进行并行处理
- 减少通信开销:分布式系统中,通信代价巨大,控制数据分布以获得最少的网络传输可以极大地提升整体性能
如下图,当userData表和Events表进行连接时,默认情况下会将两个数据集中的所有key的哈希值都求出来,将哈希值相同的记录传送到同一台机器上,之后在该机器上对所有key相同的记录进行连接操作。这样每次进行连接操作都会有数据混洗的问题,造成很大的网络传输开销。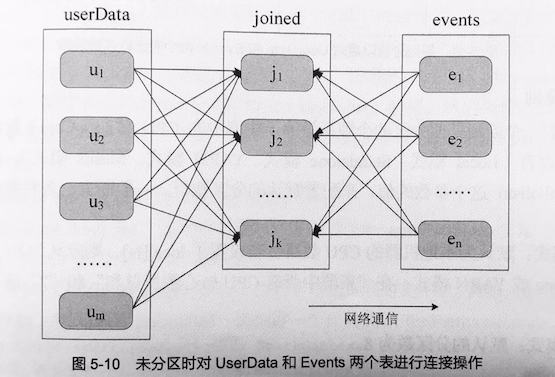
实际上,由于userData这个RDD要比events大很多,可以先对userData进行哈希分区,这样在连接时,只有events表发生了数据混洗产生网络通信,userData是在本地引用的,不会产生网络开销。可以看出,Spark通过数据分区,对于一些特定类型的操作,比如join()/leftOuterJoin()/groupByKey()/reduceByKey()等,可以大大降低网络传输开销。
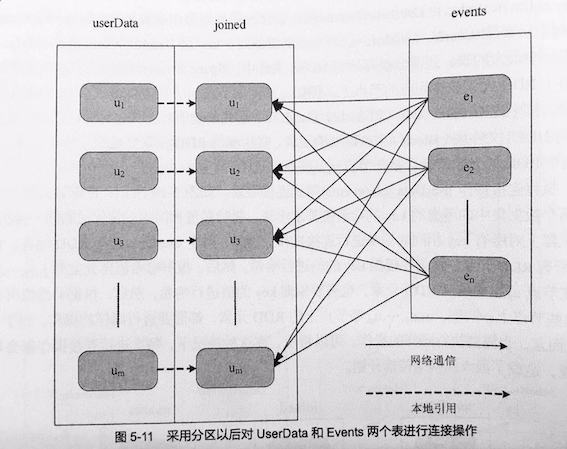
分区原则:
分区个数尽量等于集群中CPU核心(core)数目。通过spark.default.parallelism配置默认分区数目
默认分区:
- Local模式:默认是本地CPU数目
- Standalone或YARN模式:在“集群中所有CPU核心数目总和”和“2”取大值
- Mesos模式:默认分区为8
设置
创建RDD时:sc.textFile(path,partitionNum),若从HDFS读取文件,分区数为文件分片数。
repartition
|
|
- 自定义分区
|
|
键值对
- reduceByKey()
- groupByKey()
- keys()
- values()
- sortByKey()
- sortBy()
- mapValues()
- join()
- combineBykey()
|
|

