宽依赖与窄依赖
RDD之间的依赖关系可以分为两类,即宽依赖和窄依赖,宽依赖与窄依赖的区分主要是父partition与子partition的对应关系,区分宽窄依赖主要就是看父RDD的一个partition的流向,要是流向一个的话就是窄依赖,流向多个的话就是宽依赖。。
如下图所示,其中空心方框表示一个RDD,实心蓝底的框表示partition:
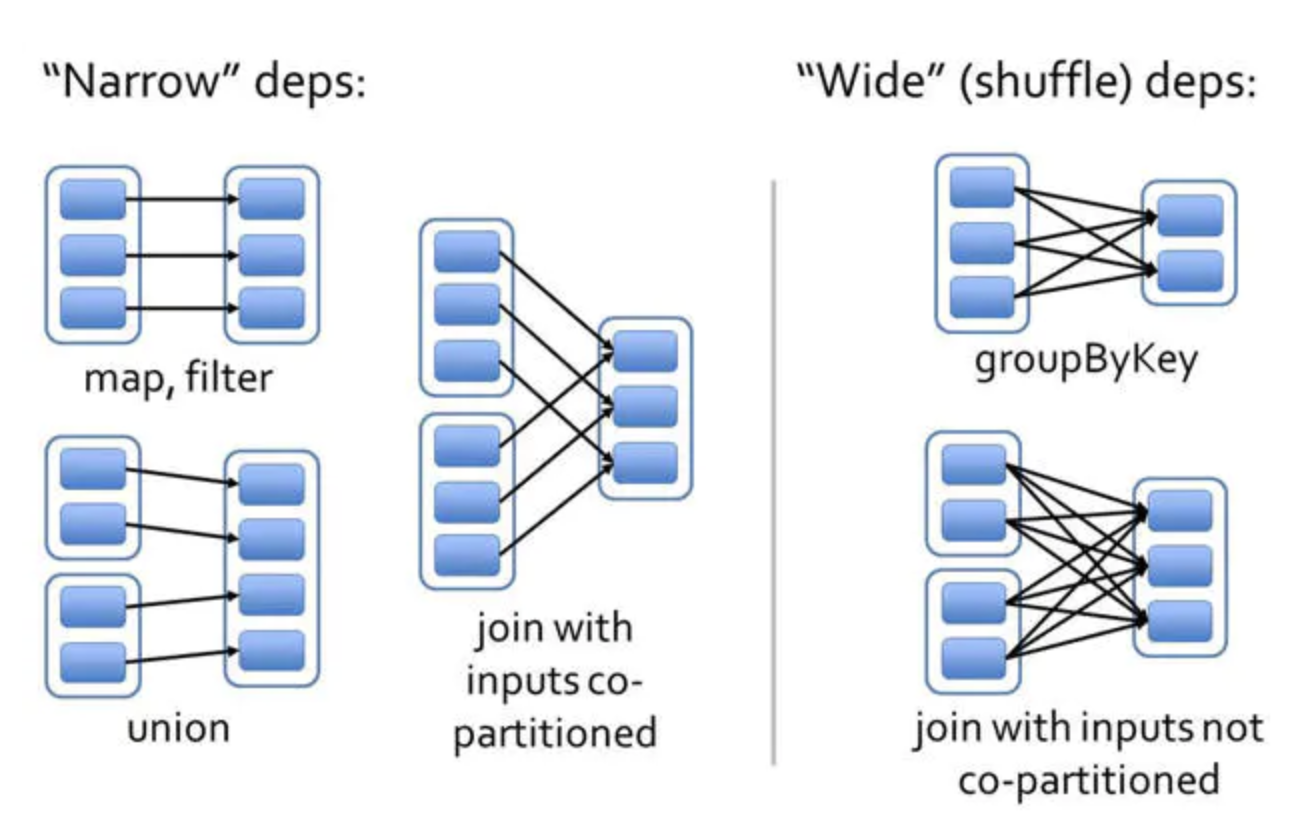
(1)窄依赖(narrow dependencies):父partition对子partition是一对一或多对一(只有一个儿子,或者说父partition的出度为1)
(2)宽依赖(wide dependencies):父partition对子partition是一对多(有多个儿子,或者说父partition的出度大于1)
窄依赖一般是对RDD进行map,filter,union等Transformations。
- union: 在两个RDD上执行union操作,返回两个父RDD分区的并集。通过相应父RDD上的窄依赖关系计算每个子RDD分区(注意union操作不会过滤重复值,相当于SQL中的UNION ALL)。
- map: 任何RDD上都可以执行map操作,返回一个MappedRDD对象。该操作传递一个函数参数给map,对父RDD上的记录按照iterator的方式执行这个函数,并返回一组符合条件的父RDD分区及其位置。
宽依赖一般是对RDD进行groupByKey,reduceByKey等操作,就是对RDD中的partition中的数据进行shuffle。
- groupByKey: 子RDD的所有Partition(s)会依赖于parent RDD的所有Partition(s),子RDD的Partition是parent RDD的所有Partition Shuffle的结果,因此这两个RDD是不能通过一个计算任务来完成的。
对两个RDD执行join操作可能产生窄依赖(如果这两个RDD拥有相同的哈希分区或范围分区),可能是宽依赖,也可能两种依赖都有(比如一个父RDD有分区,而另一父RDD没有)。
stage的划分
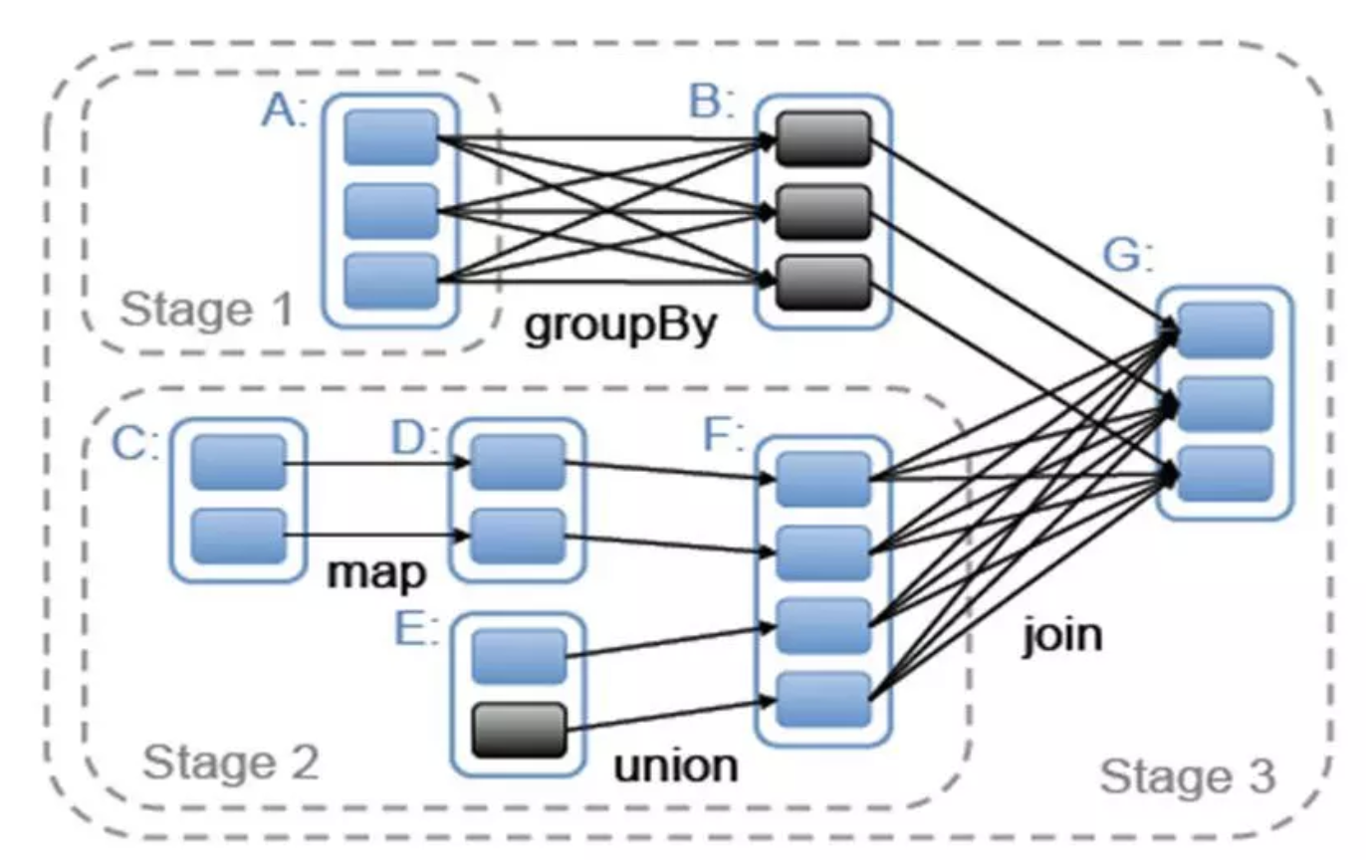
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分成互相依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。
如上图所示,A/B/C/D/E/F代表RDD,当执行算子存在shuffle操作的时候,就划分一个stage,即用宽依赖来划分stage。窄依赖会被划分到同一个stage中,这样他们就可以以管道的方式执行,宽依赖由于依赖的上游不止一个,所以往往需要需要跨节点传输数据,
宽依赖与窄依赖的对比
相比于宽依赖,窄依赖对优化很有利,主要有两点:
宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点间的数据传输,而窄依赖的每个父RDD分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
当RDD分区丢失时(某个节点故障),spark会对数据进行重算:
- 对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的
- 对于宽依赖,重算的父RDD分区对应多个字RDD分区,这样实际上父RDD中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其他未丢失分区,这就造成了多余的计算,宽依赖中子RDD分区通常来自于多个父RDD分区,极端情况下,所有的父RDD分区都要重新计算
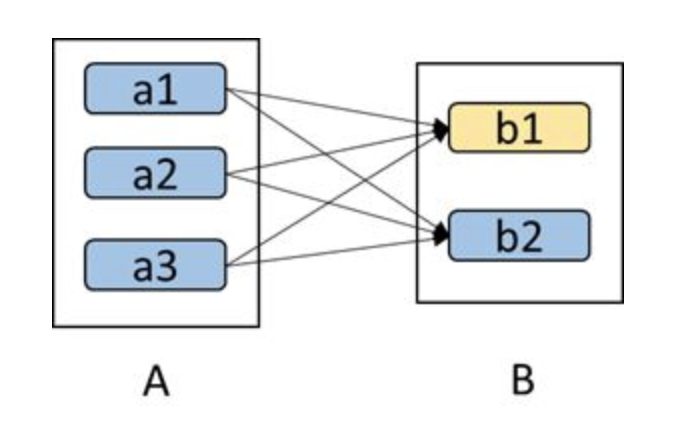
如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这样就产生了冗余计算(a1,a2,a3中对应着b2的数据)