推荐和广告已成为互联网公司的标配,这两者之间有相通的地方,推荐系统被广泛的应用于计算广告中,是其不可或缺的模块,当然推荐系统可以有更多其他的场景,比如淘宝京东的商品推荐、APP Store的应用推荐,今日头条的内容推荐等等,它需要兼顾媒体和用户这样个参与者;而广告作为互联网公司的核心业务模块,需要有推荐系统的支持,它将来自广告主的广告更有效的推荐给在媒体端观看的用户,串联的是广告主、媒体、用户三个参与方,必须要这三方玩的开心。广告的永恒目标是直接或者间接地帮助公司盈利,偏重商业,而推荐更多的是改善用户体验,提高留存,偏重产品。
这个系列,我们会从经典的点击率预估算法开始,包括LR、MLR、GBDT+LR、FM/FFM、DeepFM、Wide&Deep、DIN、DIEN、PNN、NFM、AFM、DCN等等,层出不穷的算法模型正是为了因具体的业务场景而生,即使是很微小的提升,也会对公司的收益有很大的贡献。再之后深入到计算广告和推荐系统身后更为广义的业务相关的知识、系统的架构等等。这一系列的文章会邀请业界的前辈来撰写或者转载优质的总结,争取有一个完整的展示。
第一篇,我们先从逻辑回归模型开始。
虽然目前已经有很多深度学习模型可以在不同场景下获得不错的预测广告点击率,但仍然有很多公司的广告算法部门在使用逻辑回归模型,那为何在深度时代背景下传统的逻辑回归模型在点击率预估中仍然有其用武之地呢?可以归纳为以下几点:
逻辑回归的解释性很强。当业务人员问你ecpm是如何预估出来的,你就可以对产品说,我们的模型是通过对这里的N多个有业务意义的特征进行加权求和,然后再经过一个Sigmoid函数,映射到一个0到1的区间,就预估得到了我们所需的点击率,产品一定会对你的工作表示赞同与认可;此外,当bad case出现的时候,就可以轻松解释是什么特征在作祟影响结果,而那些深度模型,八个字归纳就是:玄学调参+玄学解释。
逻辑回归的训练并行方案比较成熟。广告点击率预测需要基于大规模的样本和特征来做的,一般是上亿级别,这个时候就需要用多台机器来分布式计算参数更新;此外在线更新的时候,如果是其他模型,需要动用所有的特征,而逻辑回归得益于其线性模型的优势,可以只更新那些有变动的特征,其余不变的特征缓存起来即可,这样就大大减少了存储压力和计算代价。
逻辑回归的简单易用使得很多公司并不会花太多的精力去升级需要耗费大量精力和计算代价的深度模型,而且在数据量极大的时候,逻辑回归与其他深度模型的预测差异并不见得那么大,所以,何苦要把自己往费时费精力费钱的处境推呢;要知道,高性能机器并不是每个公司都可以承受的。算法工程师就可以把更多的时间用于特征工程,当然这两者也是一个trade-off;
接下来细致的看一看逻辑斯蒂回归具体的解释。
一、逻辑斯谛分布
介绍逻辑斯谛回归模型之前,首先看一个并不常见的概率分布,即逻辑斯谛分布。设$X$是连续随机变量,$X$服从逻辑斯谛分布是指$X$具有下列的分布函数和密度函数:
式中,$\mu$为位置参数,$\gamma>0 $为形状参数。逻辑斯谛的分布的密度函数$f(x)$和分布函数$F(x)$的图形如下图所示。其中分布函数属于逻辑斯谛函数,其图形为一条$S$形曲线。该曲线以点$(\mu,\frac{1}{2})$为中心对称,即满足
曲线在中心附近增长较快,在两端增长速度较慢。形状参数$\gamma$的值越小,曲线在中心附近增长得越快。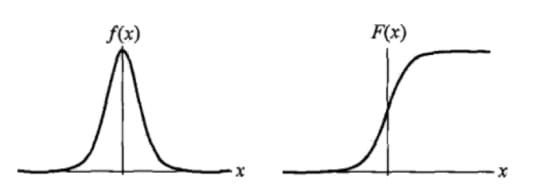
二、逻辑斯谛回归模型
线性回归的应用场合大多是回归分析,一般不用在分类问题上。原因可以概括为以下两个:
- 1)回归模型是连续型模型,即预测出的值都是连续值(实数值),非离散值;
- 2)预测结果受样本噪声的影响比较大。
2.1 LR模型表达式
LR模型表达式为参数化的逻辑斯谛函数(默认参数$\mu=0,\gamma=1$),即
其中$h_\theta{(x)}$作为事件结果$y=1$的概率取值。这里,$x\in R^{n+1},y\in \{1,0\},\theta\in R^{n+1}$是权值向量。其中权值向量$w$中包含偏置项,即$w=(w_0,w_1,···,w_n),x=(1,x_1,x_2,···,x_n)$
2.2 理解LR模型
2.2.1 对数几率
一个事件发生的几率(odds)是指该事件发生的概率与该事件不发生的概率的比值。如果事件发生的概率是$p$,那么该事件的几率为$\frac{p}{1-p}$,该事件的对数几率(log odds)或logit函数是:
对LR而言,根据模型表达式可以得到:
即在LR模型中,输出$y=1$的对数几率是输入$x$的线性函数。或者说输出$y=1$的对数几率是由输入$x$的线性函数表示的模型,即LR模型
2.2.2 函数映射
除了从对数几率的角度理解LR外,从函数映射也可以理解LR模型。
考虑对输入实例$x$进行分类的线性表达式$\theta^T$,其值域为实数域。通过LR模型表达式可以将线性函数$\theta^Tx$的结果映射到(0,1)区间,取值表示为结果为1的概率(在二分类场景中)。
线性函数的值越接近于正无穷大,概率值就越接近1;反之,其值越接近于负无穷,概率值就越接近0。这样的模型就是LR模型。
LR本质上还是线性回归,知识特征到结果的映射过程中加了一层函数映射(即sigmoid函数),即先把特征线性求和,然后使用sigmoid函数将线性和约束至(0,1)之间,结果值用于二分或回归预测。
2.2.3 概率解释
LR模型多用于解决二分类问题,如广告是否被点击(是/否)、商品是否被购买(是/否)等互联网领域中常见的应用场景。但是实际场景中,我们又不把它处理成“绝对的”分类问题,而是用其预测值作为事件发生的概率。
这里从事件、变量以及结果的角度给予解释。
我们所能拿到的训练数据统称为观测样本。问题:样本是如何生成的?
一个样本可以理解为发生的一次事件,样本生成的过程即事件发生的过程。对于0/1分类问题来讲,产生的结果有两种可能,符合伯努利试验的概率假设。因此,我们可以说样本的生成过程即为伯努利试验过程,产生的结果(0/1)服从伯努利分布。这里我们假设结果为1的概率为$h_\theta{(x)}$,结果为0的概率为$1-h_\theta{(x)}$。
那么对于第$i$个样本,概率公式表示如下:
将上面两个公式合并在一起,可得到第$i$个样本正确预测的概率:
上式是对一个样本进行建模的数据表达。对于所有的样本,假设每条样本生成过程独立,在整个样本空间中(N个样本)的概率分布(即似然函数)为:
通过极大似然估计(Maximum Likelihood Evaluation,简称MLE)方法求概率参数。具体地,第三节给出了通过随机梯度下降法(SGD)求参数。
三、模型参数估计
3.1 Sigmoid函数
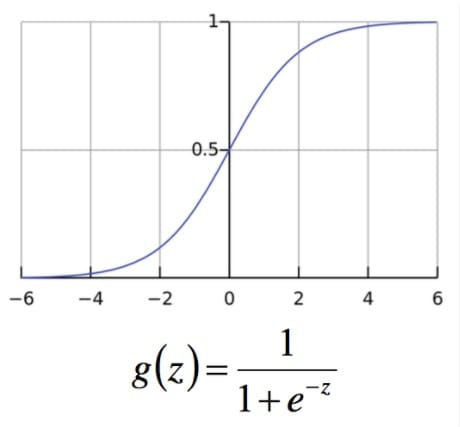
上图所示即为sigmoid函数,它的输入范围为$-\infty\rightarrow +\infty$,而值域刚好为$(0,1)$,正好满足概率分布为$(0,1)$的要求。用概率去描述分类器,自然要比阈值要来的方便。而且它是一个单调上升的函数,具有良好的连续性,不存在不连续点。
此外非常重要的,sigmoid函数求导后为: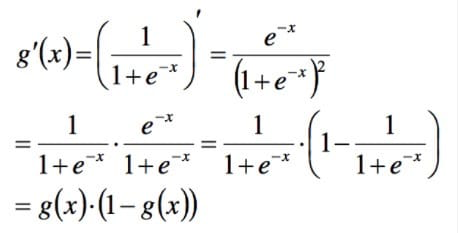
以下的推导中会用到,带来了很大的便利。
3.2 参数估计推导
上一节的公式不仅可以理解为在已观测的样本空间中的概率分布表达式。如果从统计学的角度可以理解为参数$\theta$似然性的函数表达式(即似然函数表达式)。就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大。参数在整个样本空间的似然函数可表示为:
为了方便参数求解,对这个公式取对数,可得对数似然函数:
最大化对数似然函数其实就是最小化交叉熵误差(Cross Entropy Error)。
先不考虑累加和,我们针对每一个参数$w_j$求偏导:
最后,通过扫描样本,迭代下述公式可求得参数:
其中$a$表示学习率,又称学习步长。此外还有Batch GD,共轭梯度,拟牛顿法(LBFGS),ADMM分布学习算法等都可以用来求解参数。另作优化算法一章进行补充。
以上的推导是LR模型的核心部分,在机器学习相关面试中,LR模型公式推导可能是考察频次最高的一个点。要将其熟练推导。
3.3 分类边界
知道如何求解参数后,我们看一下模型得到的最后结果是什么样的。
假设我们的决策函数为:
选择0.5作为阈值是一个一般的做法,实际应用时特定的情况可以选择不同阈值,如果对正例的判别准确性要求高,可以选择阈值大一些,对正例的召回要求高,则可以选择阈值小一些。
很容易看出,当$\theta ^Tx>0$时,$y=1$,否则$y=0$。$\theta ^Tx=0$是模型隐含的分类平面(在高维空间中,我们说是超平面)。所以说逻辑回归本质上是一个线性模型,但是这不意味着只有线性可分的数据能通过LR求解,实际上,我们可以通过特征变换的方式把低维空间转换到高维空间(kernel trick),而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些,这就涉及到了特征的交叉组合,这一块需要耗费许多人力去做人工特征组合。
- 值得阅读的相关文章
- 前深度学习时代CTR预估模型的演化之路
- CTR预估[二]: Algorithm-Naive Logistic Regression
- 科普|大家都看得懂的CTR预估解析
- 计算广告系统算法与架构综述

