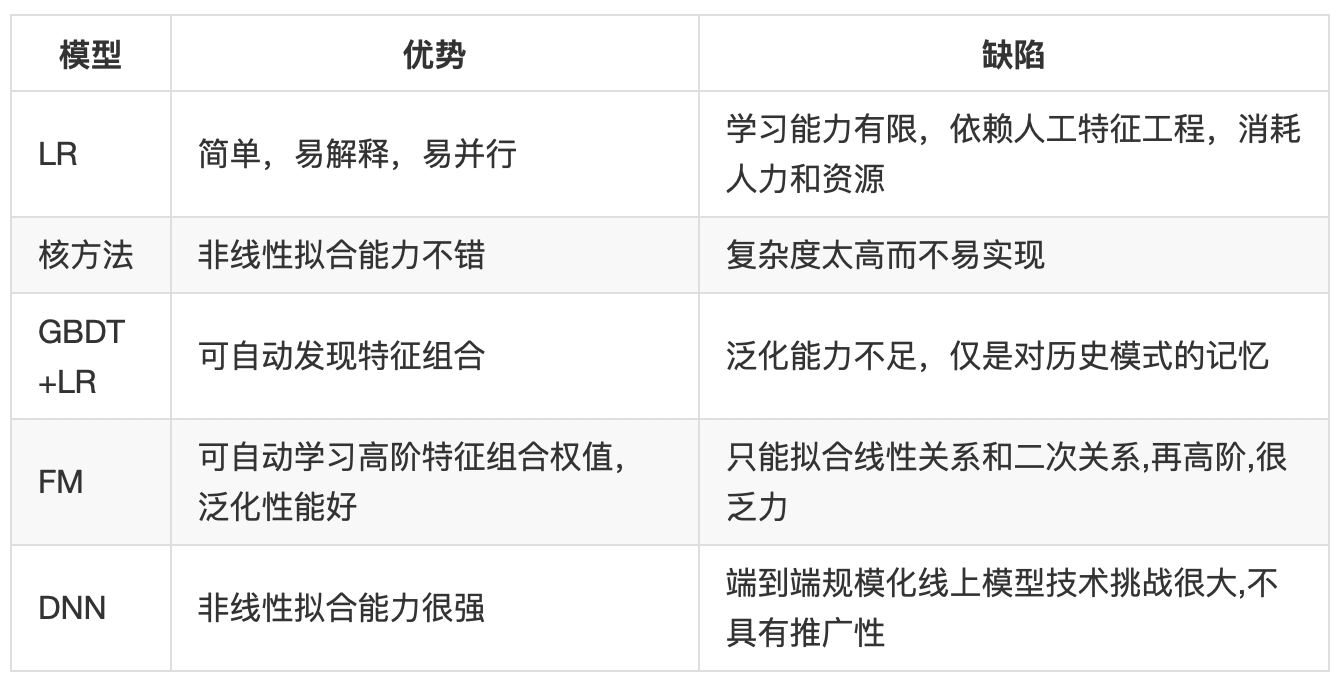
点击率预估需要解决的超高维度离散特征空间模式识别的问题,它需要算法在做到可以有效发现当前数据规律的同时,还要具有足够的泛化能力去应对线上多变的user-context-content模式,所以到目前为止有许多的CTR模型被应用于实际场景中,诸如LR、DNN、Tree Model、FM/FFM,这些模型都有各自的优势,但也存在缺陷,整理如下:
一、动机
阿里妈妈在2011年提出了MLR模型,全称Large Scale Piecewise Linear Model (LS-PLM),大规模分片线性模型,背后的思想就是根据领域知识先验将整个空间划分为多个区域,每个区域由一个特定的线性模型来拟合,区域之间平滑连接,当区域达到一定的数量,即可拟合任意复杂的非线性模式。MLR可以看做是LR模型的推广,从线性过渡到非线性,同时省去了大量的人工特征工程,可以端到端训练。
二、模型
上面讲到MLR通过先验领域知识划分空间为局部区域,然后每个区域拟合线性模型,可使用如下判别公式来刻画:
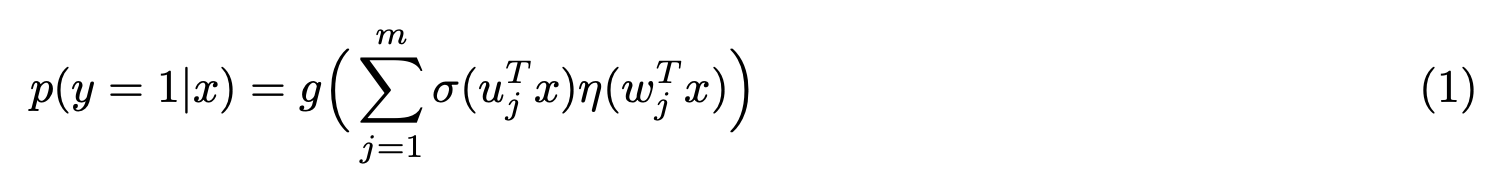
其中$\sigma$代表领域先验,决定空间划分(dividing function),$\eta$代表每个局部区域的分类预测模型(fitting function),函数$g$保证模型输出符合概率定义。
在实际中,使用softmax函数作为dividing function,使用sigmoid函数作为fitting function,以及规定$g(x)=x$,则判别函数可改写为如下: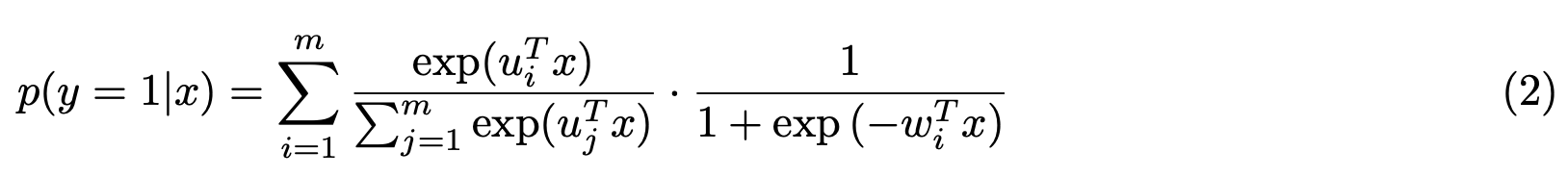
由(2)可知,该模型包含$2m$个参数,论文中使用了$L_{2,1}$正则和$L_1$正则,其中$L_{2,1}$对参数分组范数约束结构化稀疏,压缩$2m$个参数逼近零值,$L_1$则进一步产生稀疏性,使得模型兼具可解释性和泛化能力。
目标函数如下:
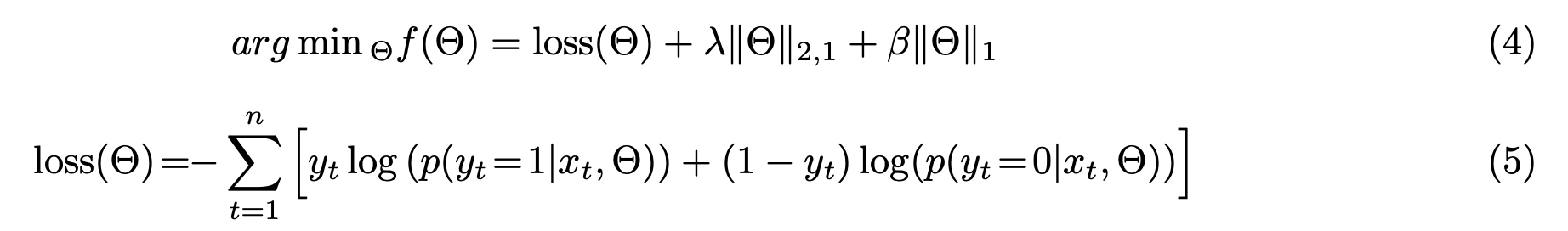
但是,引入$L_{2,1}$和$L_1$正则项之后,得到了非凸非平滑的目标函数,因为不是处处可导,所以没法用传统的梯度下降算法或者EM算法来优化,但又因为运算的效率与存储对在线预测来说很关键,模型稀疏性就必须要纳入,所以文章论文针对这个问题提出一个大规模非凸问题的优化求解方法,即利用LBFGS算法框架来根据方向导数找到最快下降方向进行参数更新,此外团队实现了一个大规模分布式系统来支持模型的高效并行训练,以下会一一介绍。
三、优化
3.1 方向导数
上面说到,目标函数非凸非光滑,无法使用导数,作者退而使用方向导数,顾名思义,方向导数就是某个方向上的导数,而且在每一个方向上都是有导数的,梯度与方向导数的关系就是在梯度方向上的方向导数最大。如下图所示,紫色箭头表示某一方向,在这个方向上的函数的方向导数如黑色实线所示
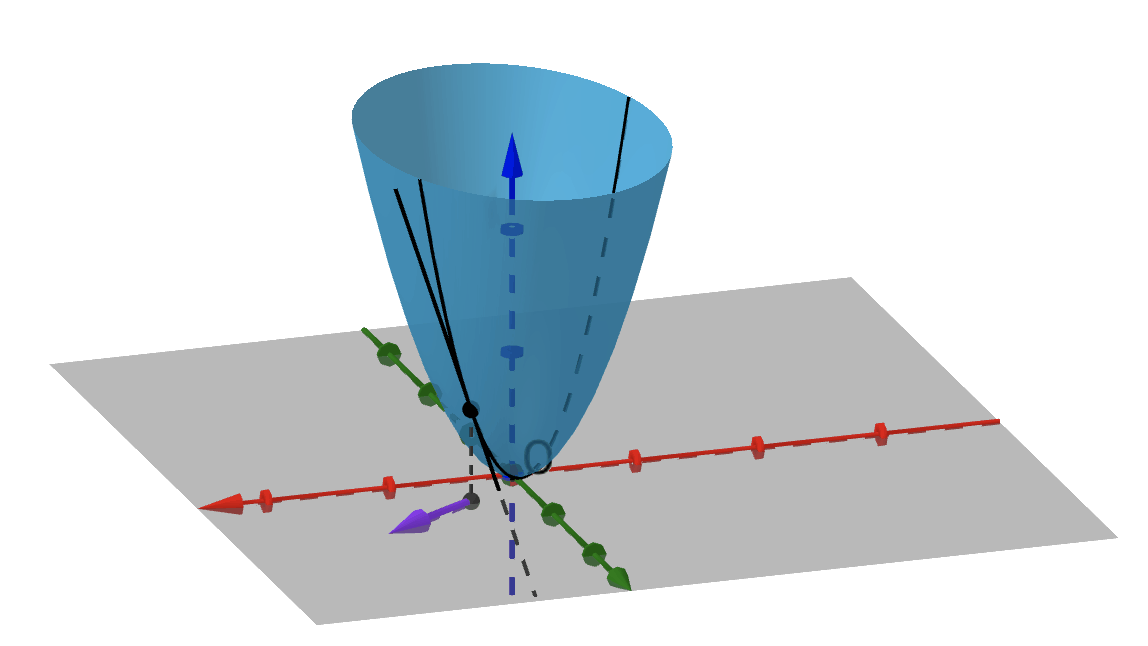
对于一个存在梯度的函数$f(x,y)$来说,其具有一阶连续偏导数,即可微,这就意味着函数$f(x,y)$在一个点$(x_0,y_0)$处的所有方向导数在一个平面上。如下图所示,红色平面即为所有方向导数所构成的平面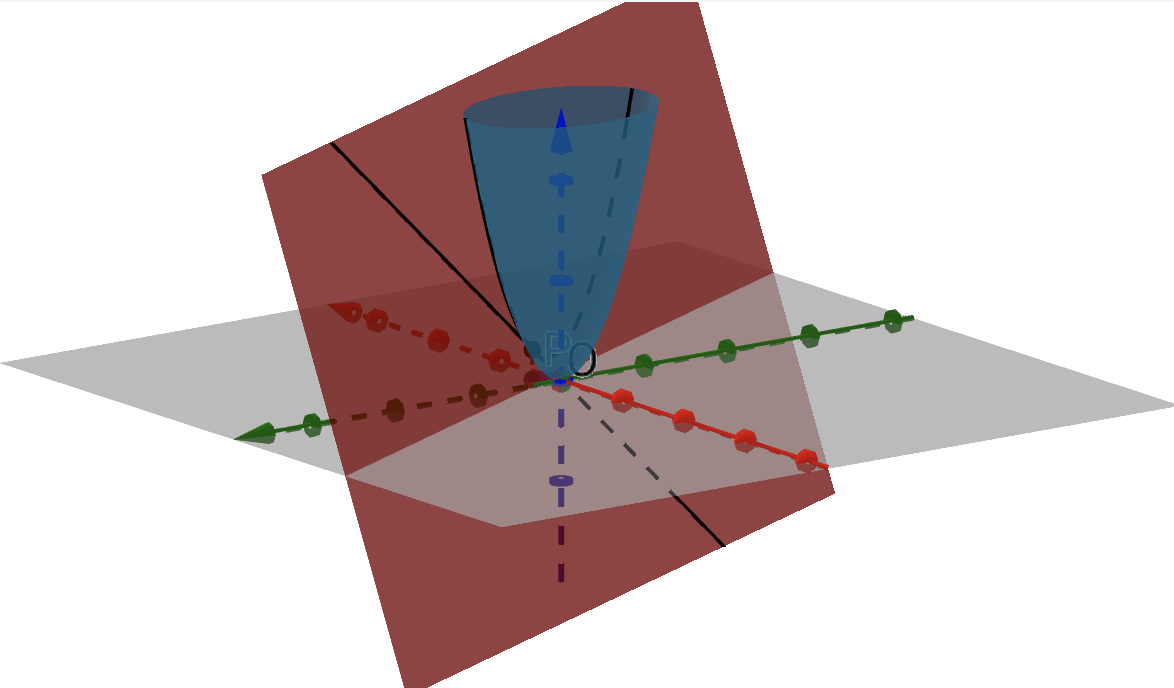
作者在附录A证明了在方向$d$上的方向导数$f^{‘}(\Theta;d)$是一定存在的,附录B求出了目标函数(4)的方向导数,我们依次看一下:
证明与求解
首先证明(4)式方向导数一定存在:
首先$f^{‘}(\Theta;d)$可以展开为三部分,分别是损失函数、$L_{2,1} $罚函数、$L_{1}$罚函数在$\Theta$处的偏导。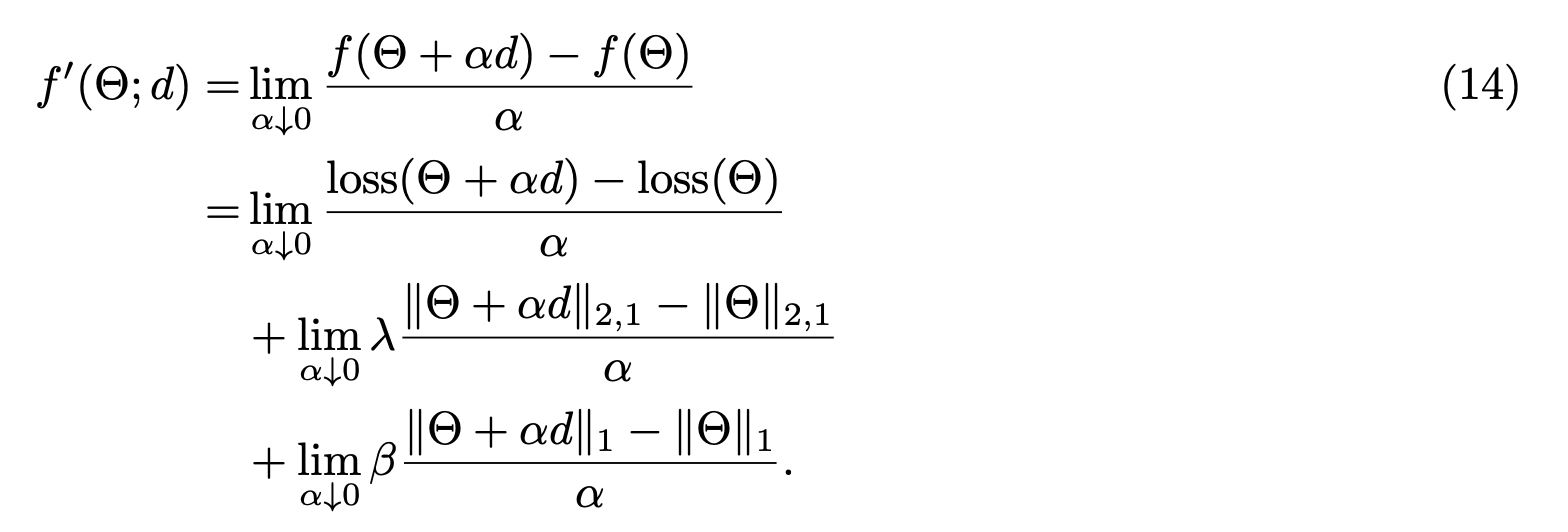
对于第一部分,可以直接求导: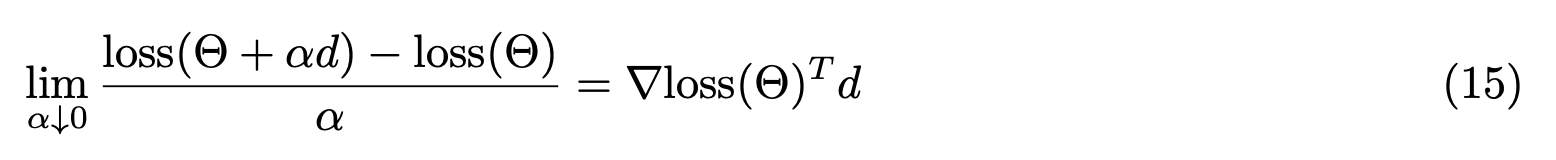
第二部分$L_{2,1} $在$||\Theta_i·||_{2,1}≠0$时,其偏导存在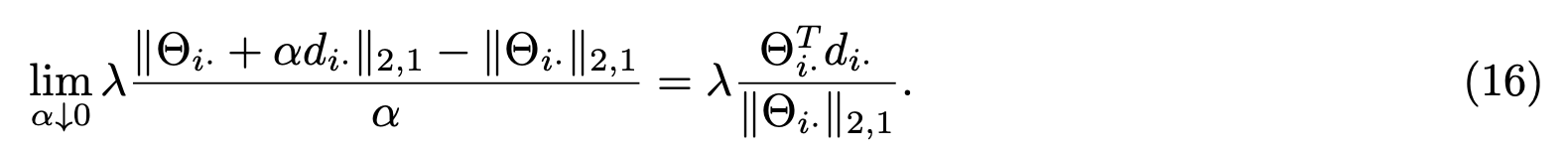
而当$||\Theta_i·||_{2,1}= 0$时,则意味着参数矩阵的行参数$\Theta_{ij}=0,1≤j≤2m$,其方向导数为: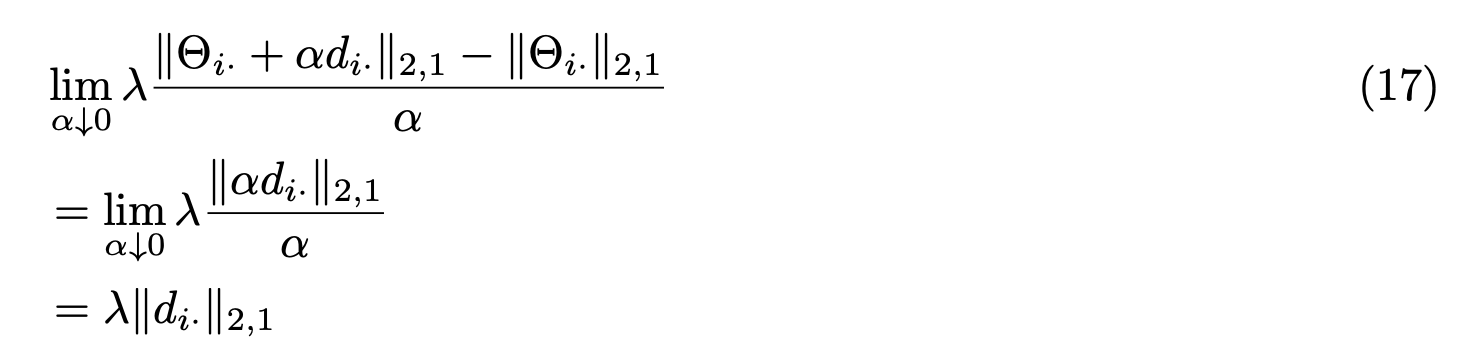
将以上两种情况整合到一起: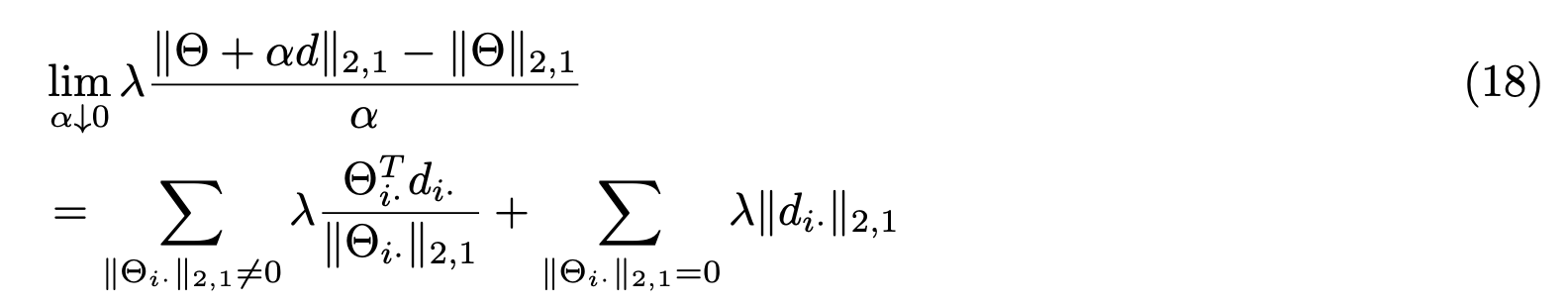
类似地,对于$L_{1}$罚函数,其导数可以表示为: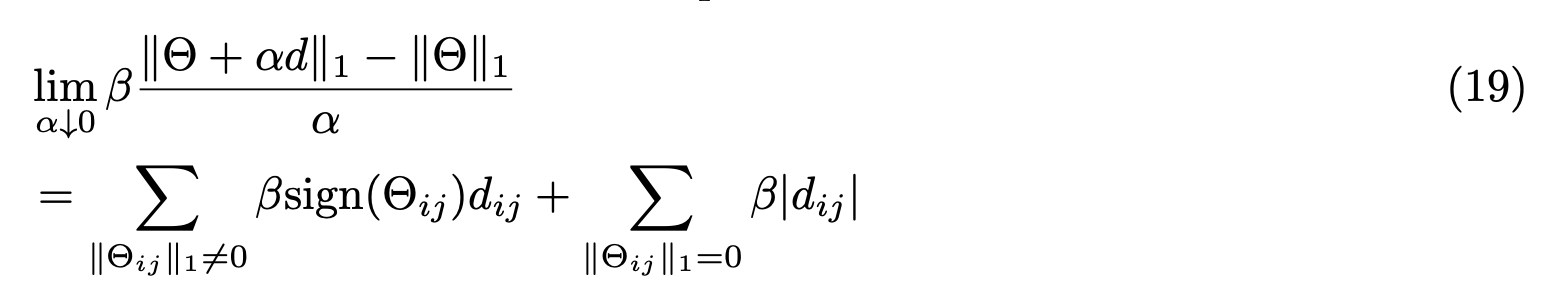
至此,我们证明了三个部分对于任意的$\Theta$和方向$d$,$f^{‘}(\Theta;d)$一定存在。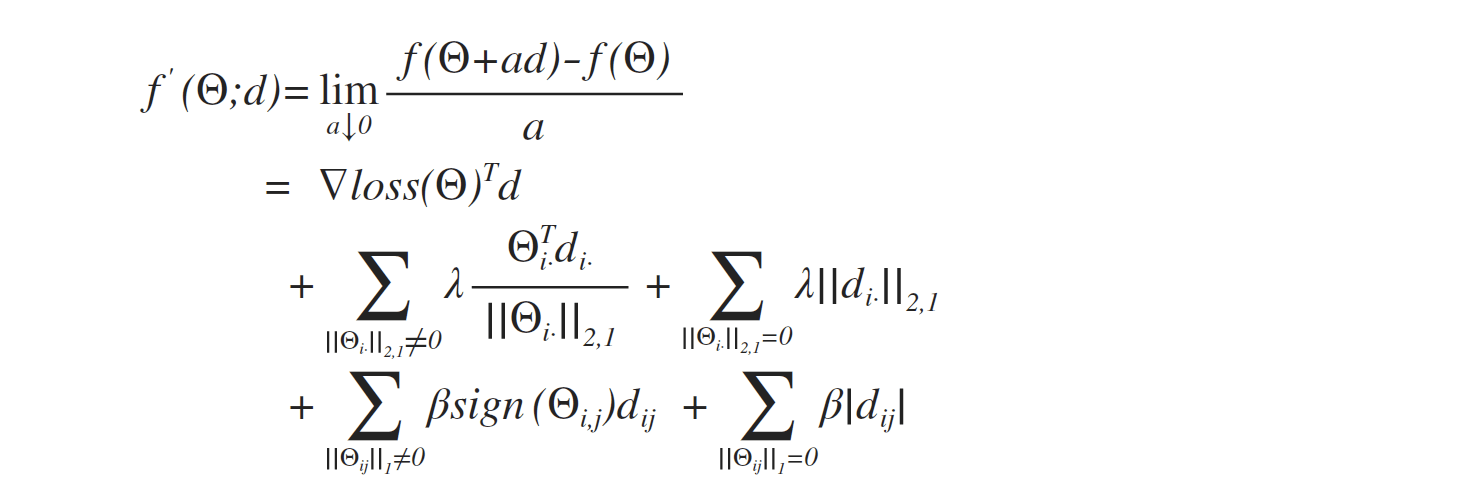
然后求解方向导数:
将问题转化为不等式约束优化问题:
采用拉格朗日乘数法求解,其中$\mu$为拉格朗日乘子: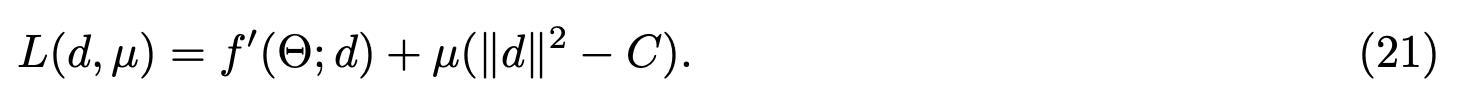
求函数$L(d,\mu)$对$d$的偏导,令为零,可分为三种情况,过程略,最终求解得到如下:
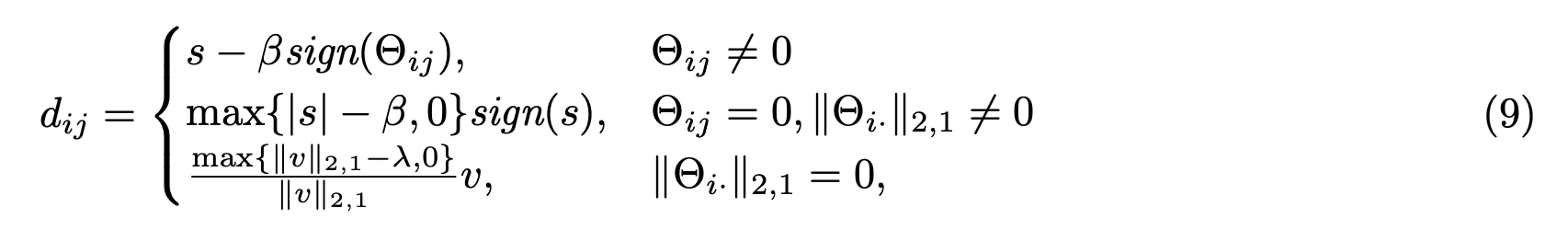
其中: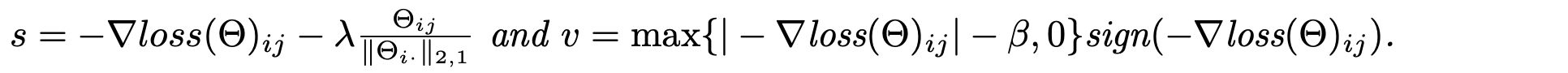
至此我们得到了方向导数,接下里的问题就是如何利用方向导数来更新参数,文中使用LBFGS框架,并采取了类似于OWLQN算法的做法,接下来介绍一下论文是如何优化的。
3.2 LBFGS
大多数的数值优化算法都是迭代式的,优化的目的就是希望参数序列收敛于$x^*$,从而使$f(x)$最优化。
在牛顿法中使用二阶泰勒展开来近似目标函数: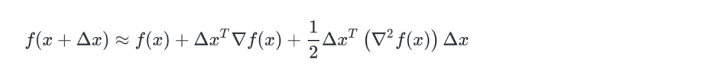
令$g_n$表示$f$在$x_n$处的梯度,$H_n$表示目标函数$f$在$x_n$处的Hessian矩阵,简化$f(x+\Delta x)$=$h_n(\Delta x)$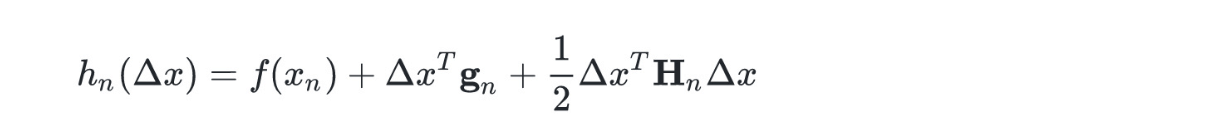
求导令其为零,得到的$\Delta x$都是他的局部极值点,若$f$是凸函数,则$H$为正定矩阵,则此时局部最优即为全局最优。
得到如下更新式:
其中步长$a$可采用line search的方法,比如backtracking line search方法,即选用逐渐递减的步长。
其迭代算法伪代码如下:

但实践中,模型参数都是超高维度的,根本无法计算Hessian矩阵及其逆,BFGS就是为了解决这个问题,他使用了一种QuasiUpdate的策略生成$H_n^{-1}$的近似,伪代码如下:

其中$\{s_k\}$与$\{y_k\}$保存的是输入和梯度的变化量,即$s_k = x_k-x_{k-1}$,$y_k = g_k-g_{k-1}$,初值$H_0^{-1}$选取任意对称的正定矩阵。:
具体的QuasiUpdate那一步的推导略复杂,略过,最终BFGS的迭代伪代码如下:

其中 $\rho_n = (y_n^Ts_n)^{-1}$
只要给定方向d,该算法可以直接计算出$H_n^{-1}$,却不需要求出$H_n^{-1}$。
LBFGS是对BFGS的改进,因为BFGS拟牛顿虽然无需计算海森矩阵,但仍然需要保存每次迭代的$s_n$与$y_n$的历史值。内存负担依然很重,L-BFGS是limited BFGS的缩写,简单地只使用最近的m个$s_n$与$y_n$记录值,以此来近似计算$H_n^{-1}g_n$
在BFGS的迭代过程中,需要使用梯度信息,但因为我们的目标函数有$L_1$正则和$L_{2,1}$正则项,不是处处可导的,这时候OWLQN就上场了
3.3 OWLQN
OWLQN算法在LBFGS框架下针对非凸非平滑函数优化主要做出了两点改进:
1、在不可导处用次梯度取代梯度
当模型参数不为零时,此时可导,按一般方法计算即可;当模型参数为零时,此时不可导,正则项的左偏导数为${ \partial }_{ i }^{ - }f(x)$,右偏导数${ \partial }_{ i }^{ + }f(x)$。
如何确定在零的位置的时候用左导数还是右导数呢?做法是防止象限穿越,通俗的讲就是在负象限的时候减去正值,在正象限的时候减去负值(加上正值)
2、在line search的时候做象限约束
当参数不在零点时,line search保持在参数所在象限内搜索;当参数在零点时,参数在次梯度约束的象限内进行line search
以下公式可以描述以上两点改进
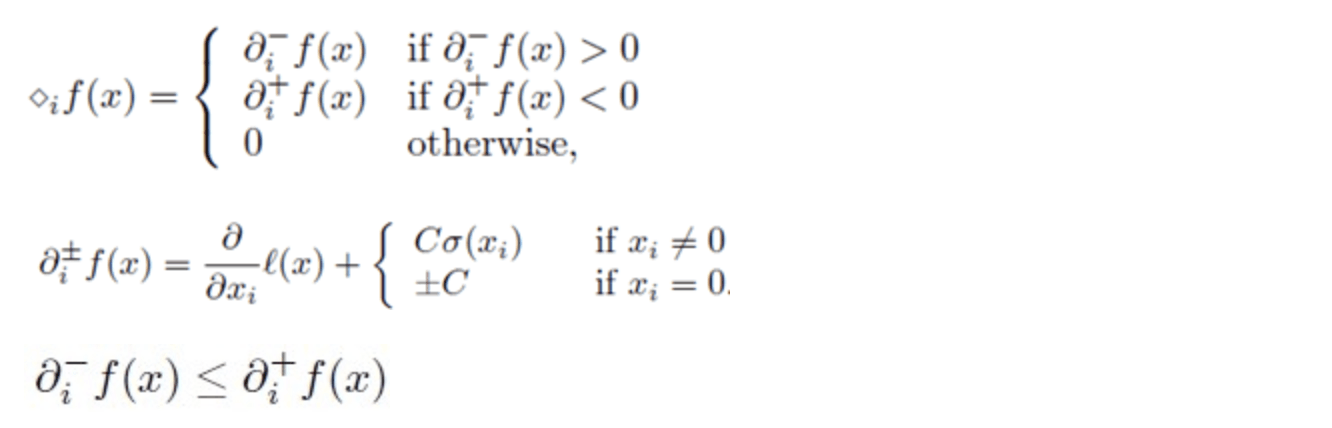
3.4 MLR的优化算法
MLR中使用的优化算法是从OWLQN改进过来的,主要有三个地方的变化:
- MLR使用方向导数来优化目标函数,而不是OWLQN的次梯度
- MLR对更新方向p进行了象限约束:非正定时直接用方向导数作为搜索方向,否则要进行象限约束在方向导数所在象限内。
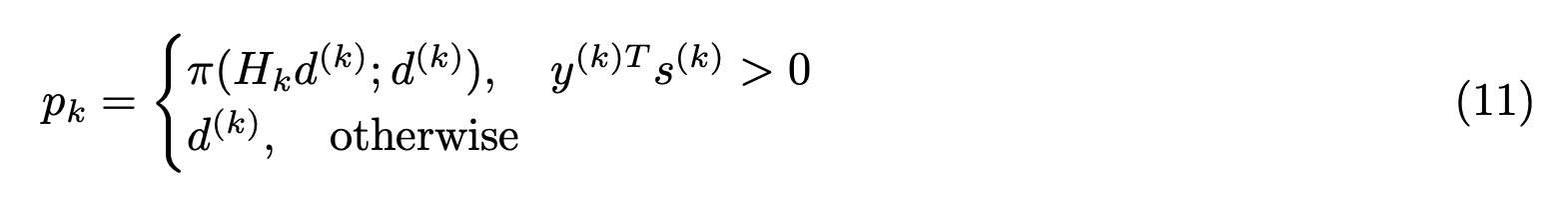
- 线性搜索的象限约束不同,当MLR参数不在零点时,line search保持在参数所在象限内搜索,在零点时,参数在方向导数约束的象限内进行line search

给定更新方向,MLR使用了 backtracking line search方法找到合适的步长$\alpha$,其迭代更新公式如下:
MLR最终的优化算法伪代码如下:

四、分布式
4.1 参数服务器
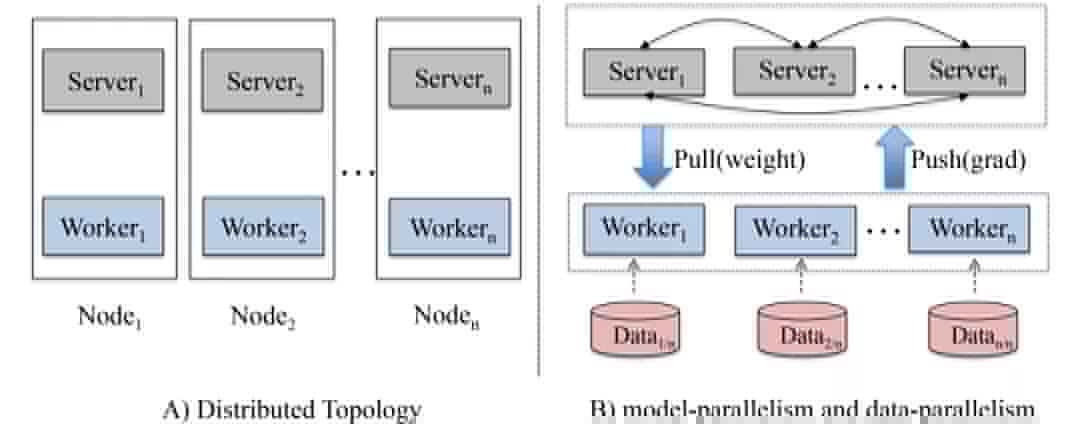
4.2 Common Feature Trick
用户在一次浏览的过程中遇到多个广告,每个广告都会支持组成一条样本,这样会导致很多特征重复使用,比如用户的人口统计特征,用户基于历史行为的兴趣偏好等,为了解决重复计算的问题,文中提出在向量内积的过程中分成两部分:
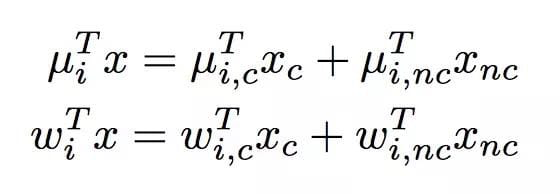
从这个事实出发,训练就可以下列三个Trick:
- 训练过程中把有common Feature的样本放在一组,且仅仅保存一次以节省内存
- 优化参数时,Common Feature的只更新一次损失函数
最终效果如下,内存开销减少65%,时间开销减少91%,效果很明显:
五、高级特性
在阿里妈妈团队写的MLR分享文章里面,提及了以下几点MLR的高级特性:
- 领域知识先验,这个分别体现在上文说到的dividing function和fitting function,他是基于领域的先验知识来设定dividing function和fitting function,比方说以用户的特征设计分片函数,以广告的特征设计拟合函数,这是基于不同人群具有聚类特性,同一类人群对广告有类似的偏好这样一个前提,此外这样的结构先验也有助于缩小解空间,更容易收敛!
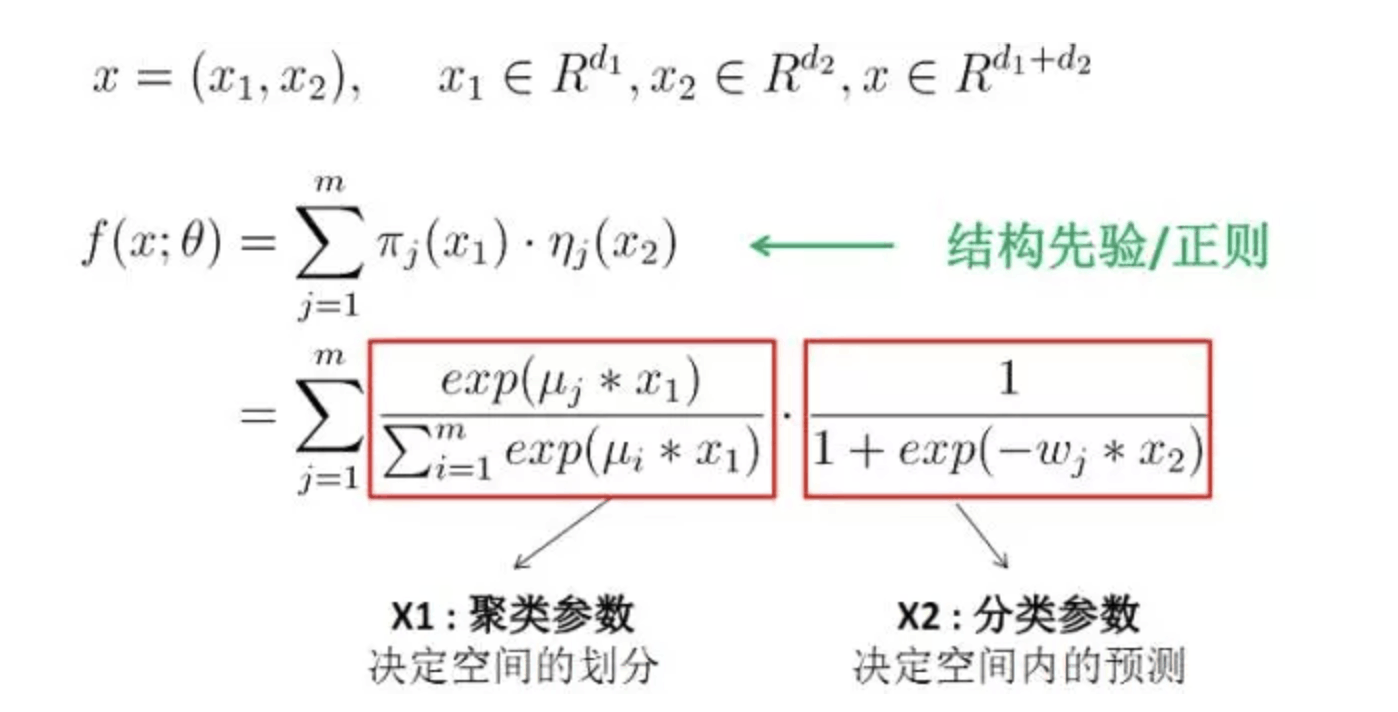
- 加入线性偏置,因为特征的差异导致点击率天然存在一些差异,比如说位置和资源位,所以在损失函数中加入如公式所示的线性偏置,实践中对位置bias信息的建模,获得了4%的RPM提升效果。

模型级联,与LR模型级联式联合训练,实践中发现一些强feature配置成级联模式有助于提高模型的收敛性,比如以统计反馈类特征构建第一层模型,它的输出(如下图中的FBCtr)级联到第二级大规模稀疏ID特征体系中去,这样能够有助于获得更好的提升效果。
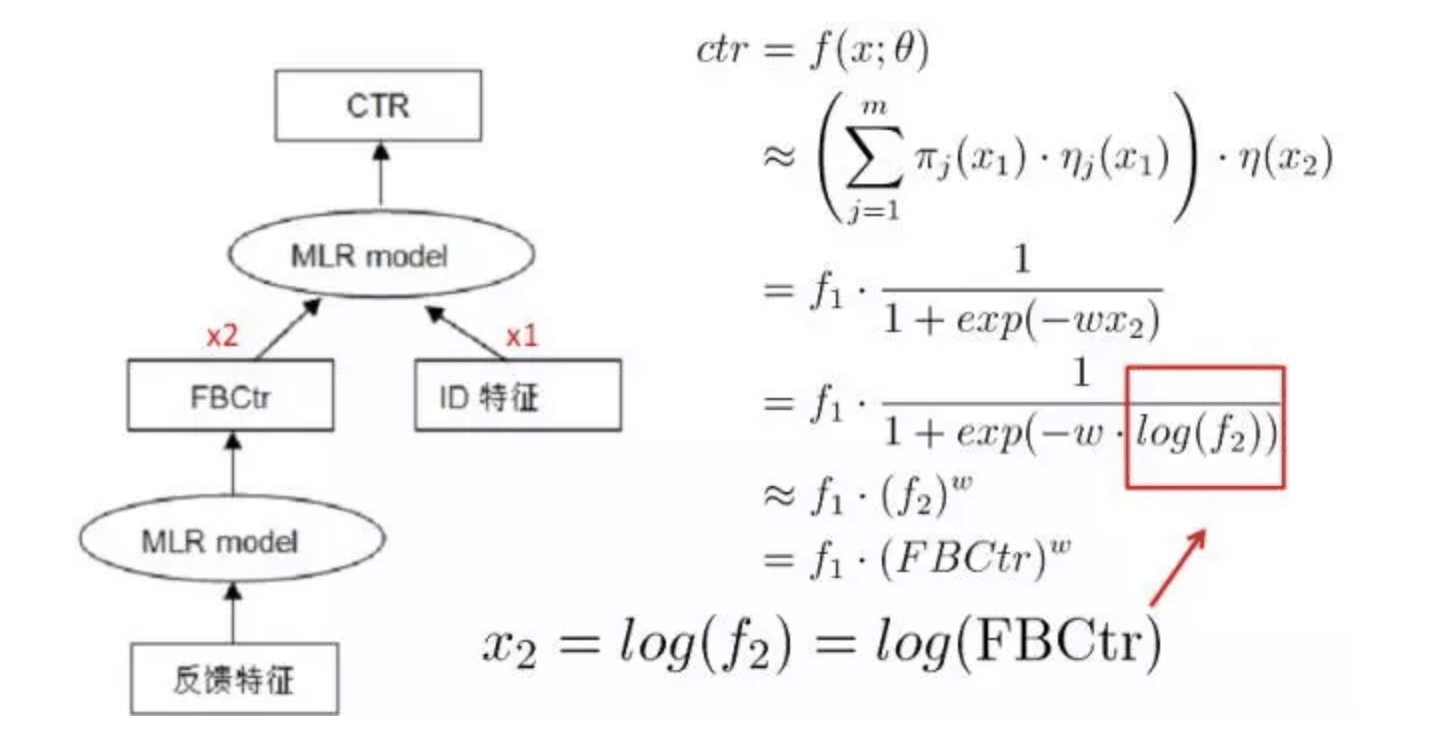
增量训练。实践证明,MLR通过结构先验进行pretrain,然后再增量进行全空间参数寻优训练,会获得进一步的效果提升。同时增量训练模式下模型达到收敛的步数更小,收敛更为稳定。在我们的实际应用中,增量训练带来的RPM增益达到了3%。

六、业务现状
阿里妈妈团队主要将MLR主要应用于定向广告的CTR预估和定向广告的Learning to Match:
对于定向广告CTR,他们将用户画像特征、用户历史行为特征、广告画像特征组成2亿为的embedding向量,直接放到MLR模型中训练,并且采用了线性偏置、领域知识先验、增量训练的高级特征,提升了CTR预估的精度。
Learning to Match,即基于用户的人口属性、历史行为等信息来猜测用户可能感兴趣的广告集合,一般会使用规则匹配和协同过滤来做召回模块,阿里妈妈研发了基于MLR的learning to match算法框架,首先基于用户的行为历史来学习用户个性化兴趣,召回候选集,MLR框架很容易融合将不同的特征源、标签体系,省去交叉组合的成本,灵活性很高。
参考资料:

