这一章节我们来看一下在Spark常用来进行聚合操作的Pair RDD,其实类似于字典,由key-value对构成,同样的,Pair RDD也有很多的操作接口,比如reduceByKey()、join(),下面会逐一对介绍,很多语言的语法都是相同的,这里的聚合操作就类似于SQL中的group by或者python中的groupby,所以领会起来也不难。
然后再看一下数据分区相关的内容,数据分区对分布式集群上跑数据来说及其重要,一个小的优化就会极大的降低时间成本和内存开销,这一块也是写Spark Job过程中需要重点关注的。
一、Pair RDD创建
|
|
二、Pair RDD转化操作
- 聚合操作
|
|
- 数据分组
|
|
- 连接
内连接 => join()
左连接 => leftOuterJoin()
右连接 => rightOuterJoin()
- 排序
|
|
三、Pair RDD行动操作
上一节说到的行动操作都适用于Pair RDD,此外Pair RDD还有以下行动操作:
|
|
四、数据分区
在执行以上的聚合或分组操作时,可以给定Spark的分区数,每一个RDD都有固定给定数目的分区数,Spark会根据集群大小推断有意义的默认值,当然我们也可以对并行度进行调优来获取更好的性能表现。
|
|
coalesce和repartition
此外Spark还提供了repartition()函数,以用于在分组和聚合操作之外改变分区,repartition()函数会先把数据通过网络进行混洗,创建新的分区集合。但这样网络开销会很大,coalesce()函数正是对此做了优化。我们可以通过rdd.getNumPartitions查看RDD分区数。
coalesce()函数中有两个传入参数,coalesce(numPartitions,shuffle),其中numPartitions为指定分区数,shuffle为是否进行shuffle,默认为false,若numPartitions大于原有的分区数,必须指定shuffle=True;但避免进行shuffle可以节省网络开销。
repartition()函数只有一个传入参数,repartition(numPartitions),因为它指定了shuffle为True。
combineByKey()分区数据处理过程
combineByKey是Spark中一个比较核心的高级函数,groupByKey、reduceByKey的底层都是使用combineByKey实现的,我们来看一下combineByKey()是如何处理分区数据的。
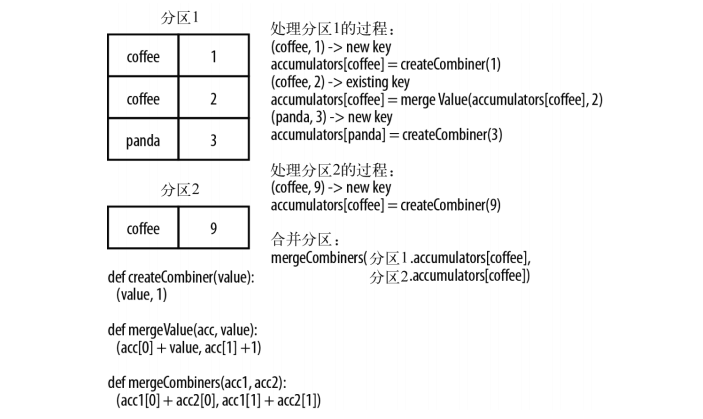
这个数据流图中出现了三个函数createCombiner、mergeValue、mergeCombiners,分别看一下概念:
createCombiner: combineByKey()会遍历分区中的所有元素,因此每个元素的键要么新出现,要么之前遇到过。若是一个新元素, combineByKey()会使用一个createCombiner() 函数创建那个键对应的累加器的初始值。
mergeValue: 如果键在之前遇到过,可以使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并。
mergeCombiners: 每个分区独立操作,所以对于同一个键可有多个累加器。若多个分区都有同一个键的累加器,就需要用mergeCombiners() 将各个分区的结果合并。
这样就很好理解了,整个combineByKey的过程就是在不同的分区上执行类似的操作,遇到新键,执行createCombiner,遇到已存在的键,执行mergeValue,最终对所有分区执行mergeCombiners。
数据分区优化
Spark程序可以通过控制RDD分区方式来减少通信开销。举个具体的例子,下面这段scala代码计算了查阅自己订阅主题页面的用户数量。
|
|
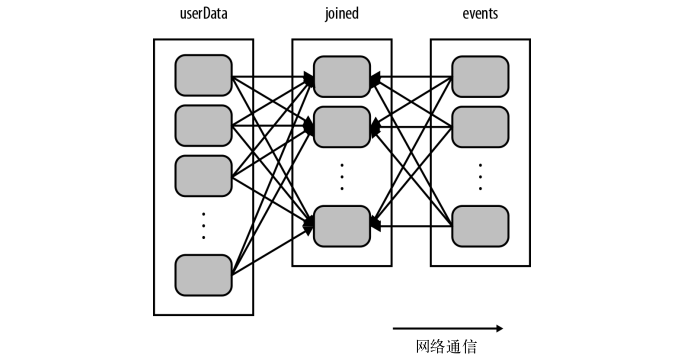
但这里有个问题就是,每次调用processNewLogs时,会有一个join操作,会将两个数据集中的所有键的哈希值都求出来,将该哈希值相同的记录通过网络传到同一台机器上,然后在那台机器上对所有键相同的记录进行连接操作。假如userdata表很大很大,而且几乎是不怎么变化的,那么每次都对userdata表进行哈希值计算和跨节点的数据混洗,就会产生很多的额外开销。这个过程的join操作如下:
如何解决网络开销的问题呢?可以再程序开始时,对userdata表使用partitionBy()转化操作,将这张表转为哈希分区。具体实现如下:
|
|
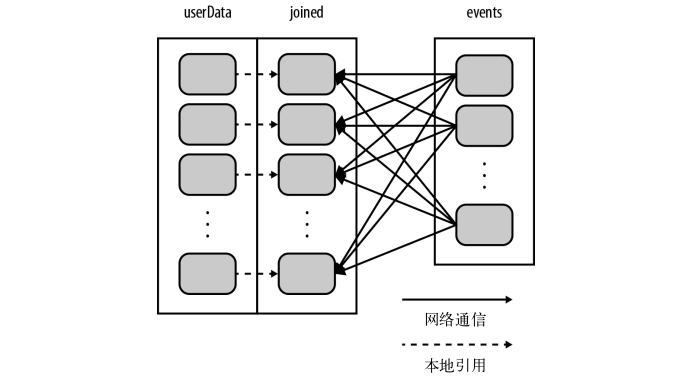
构建userData时调用了partitionBy(),在调用join()时,Spark只会对events进行数据混洗操作,将events中特定UserID的记录发送到userData的对应分区所在的那台机器上。这样,通过网络传输的数据就大大减少,程序运行速度也可以显著提升。partitionBy()是一个转化操作,因此它的返回值是一个新的RDD。还有一点要注意,这里必须要持久化才可以在后面用到RDD时不重复分区操作。
scala可以使用RDD的partitioner属性来获取RDD的分区方式,它会返回一个scala.Option对象。
可以从数据分区中获益的操作有cogroup() , groupWith() , join() , leftOuterJoin() , rightOuterJoin() , groupByKey() , reduceByKey() , combineByKey()以及lookup()。
参考资料:《Spark快速大数据分析》

